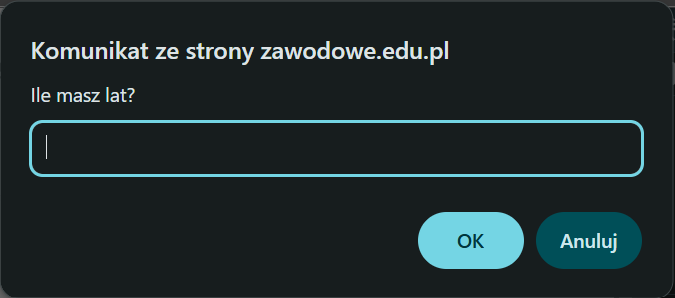
Pytanie 1
Efekt przedstawiony na obrazie, wykonany za pomocą edytora grafiki rastrowej, to

A. pikselizacja.
B. szum RGB.
C. grawerowanie.
D. rozmycie Gaussa.
Twoja odpowiedź jest prawidłowa! Wybrany efekt to pikselizacja. Pikselizacja polega na zmniejszeniu rozdzielczości obrazu do poziomu, gdy każdy piksel staje się widoczny dla oka. Efekt ten charakteryzuje się wyraźnymi, dużymi blokami pikseli tworzącymi obraz. Jest to efekt często stosowany w grafice komputerowej, szczególnie w celu nadania grafice stylu retro. Pikselizacja była też kluczowym elementem estetyki gier wideo z lat 80. i 90., kiedy to technologiczne ograniczenia sprzętowe wymuszały korzystanie z niskiej rozdzielczości obrazu. W dzisiejszych czasach efekt pikselizacji jest często stosowany celowo, dla uzyskania określonego efektu artystycznego lub dla celów nostalgicznych. Warto jednak pamiętać, że nadmierne pikselizowanie obrazu może prowadzić do utraty szczegółów, dlatego zawsze warto dobrze przemyśleć zastosowanie tego efektu.