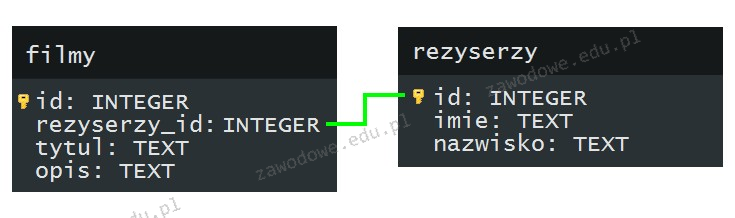
Pytanie 1
Określenie powiązań między tabelami w bazie danych MySQL realizuje klauzula
A. ORDER BY
B. REFERENCES
C. PRIMARY KEY
D. INDEX
Podczas analizy pozostałych dostępnych odpowiedzi, należy zauważyć, że nie są one odpowiednie do ustalania relacji pomiędzy tabelami w MySQL. Klauzula INDEX służy do poprawy wydajności zapytań poprzez tworzenie indeksów na kolumnach, co przyspiesza dostęp do danych. Indeksy są używane głównie w kontekście optymalizacji zapytań, a nie do definiowania relacji między tabelami. Z kolei klauzula ORDER BY jest używana do sortowania wyników zapytań według określonych kolumn. Nie ma ona wpływu na strukturalne powiązanie danych w bazie, a jedynie na sposób ich prezentacji w wynikach zapytań. Ostatnia z wymienionych opcji, PRIMARY KEY, jest kluczowym elementem w każdej tabeli, który zapewnia unikalność danych w kolumnie lub zestawie kolumn. Chociaż klucz podstawowy jest niezbędny do identyfikacji rekordów, sam w sobie nie tworzy relacji między tabelami, ale raczej definiuje unikalny identyfikator dla wierszy w danej tabeli. Warto zatem zauważyć, że klauzula REFERENCES jest jedynym poprawnym wyborem do ustalenia relacji między tabelami, podczas gdy pozostałe opcje pełnią inne funkcje w kontekście zarządzania danymi.