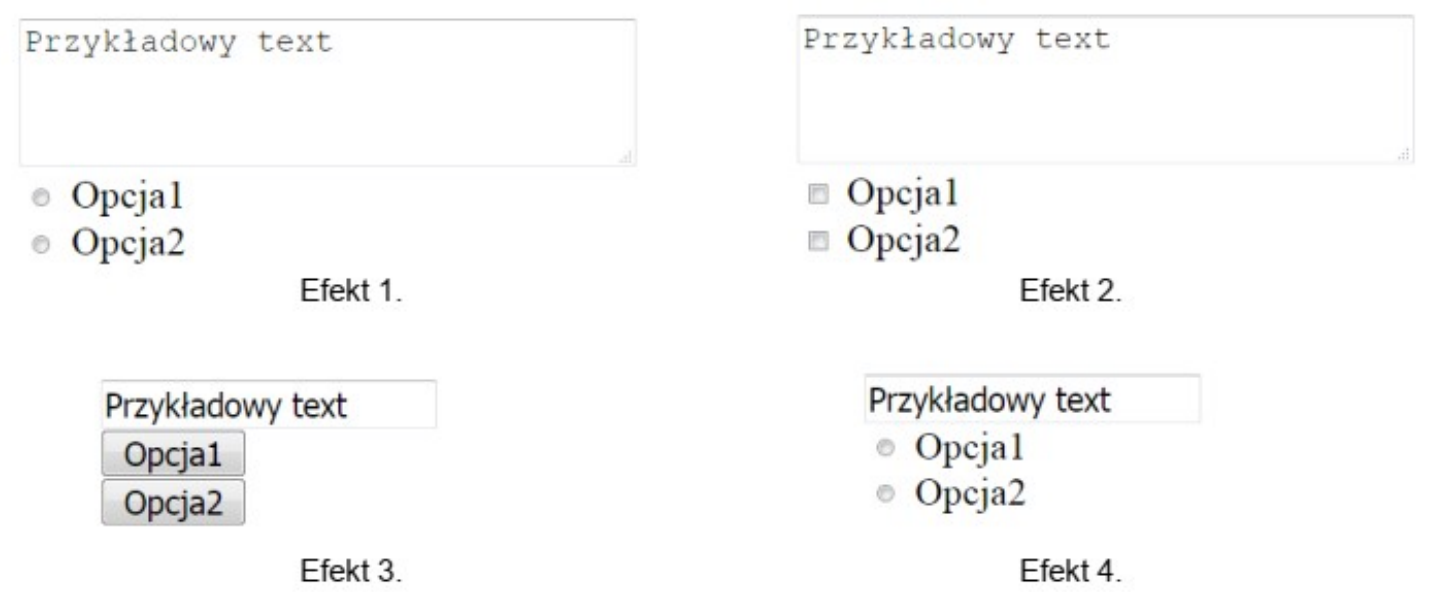
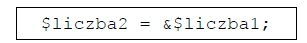Pytanie 1
Funkcja PHP var_dump() wyświetla informację na temat zmiennej: jej typ i wartość. Wynikiem dla przedstawionego fragmentu kodu jest:
$x = 59.85; var_dump($x);
A. int(59)
B. float(59.85)
C. string(5) "59.85"
D. array(2) { [0]=> int(59) [1]=> int(85) }
Gratulacje, Twoja odpowiedź jest poprawna! W poprawnej odpowiedzi, wartość zmiennej $x była 59.85, co jest liczbą zmiennoprzecinkową, a więc typem tej zmiennej jest float. Funkcja PHP var_dump() służy do wyświetlania informacji o zmiennej, w tym jej typu i wartości. Zatem wynikiem jej wykonania dla zmiennej $x inicjowanej wartością 59.85 jest float(59.85). To jest jeden z przykładów, gdzie rozumienie typów danych w PHP jest kluczowe. Zrozumienie typu float pozwoli Ci na prawidłową manipulację danymi, co jest niezwykle ważne w programowaniu. Jest to szczególnie istotne, gdy porównujesz różne wartości lub przekształcasz jedne typy danych w inne. Pamiętaj, że PHP jest językiem o słabej typizacji, co oznacza, że konwersja typów może nastąpić automatycznie w niektórych kontekstach, więc zawsze warto wiedzieć, jakiego typu jest dana zmienna.