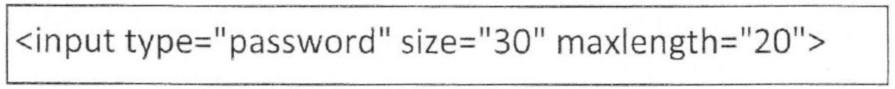Pytanie 1
Którą funkcję z menu Kolory programu GIMP użyto, w celu uzyskania efektu przedstawionego w filmie?
A. Inwersja.
B. Krzywe.
C. Barwienie.
D. Progowanie.
Wiele osób myli w GIMP-ie różne narzędzia z menu Kolory, bo na pierwszy rzut oka kilka z nich „mocno zmienia” obraz. Jednak efekt pokazany na filmie, gdzie obraz staje się dwuwartościowy (czarno-biały, bez półtonów), jest typowym działaniem funkcji Progowanie. Kluczowe jest tu zrozumienie, czym różnią się od siebie dostępne operacje. Krzywe służą do zaawansowanej korekcji tonalnej i kontrastu. Można nimi mocno przyciemnić lub rozjaśnić wybrane zakresy jasności, robić tzw. efekt kontrastu „S”, korygować prześwietlenia itd. Ale nawet przy bardzo agresywnych ustawieniach krzywych obraz nadal zawiera półtony – pojawiają się stopniowe przejścia między odcieniami, a nie ostre odcięcie na zasadzie czarne/białe. To świetne narzędzie do retuszu zdjęć, ale nie do uzyskania efektu progowania. Inwersja (Kolory → Inwersja) po prostu odwraca wartości kolorów lub jasności: jasne staje się ciemne, czerwony zmienia się na cyjan, zielony na magentę itd. To jak negatyw fotograficzny. Struktura szczegółów pozostaje identyczna, zmienia się tylko ich „biegun”. Nie pojawia się żadne odcięcie progowe, więc obraz wciąż ma pełne spektrum odcieni. W praktyce inwersja przydaje się np. przy przygotowaniu masek lub pracy z materiałami skanowanymi, ale nie generuje typowego, „plakatowego” efektu czerni i bieli jak progowanie. Barwienie z kolei (Kolory → Barwienie) służy do nadania całemu obrazowi jednolitego odcienia, zwykle po wcześniejszym sprowadzeniu go do skali szarości. Można w ten sposób uzyskać np. sepię, niebieski ton nocny albo dowolny kolorystyczny „filtr”. Jasność i kontrast lokalny pozostają bardzo podobne, zmienia się dominująca barwa. To zupełnie inna kategoria operacji niż progowanie, które pracuje na poziomie progów jasności, a nie na poziomie koloru. Typowym błędem jest patrzenie tylko na to, że „obraz bardzo się zmienił” i przypisywanie tego narzędziom takim jak krzywe czy inwersja. W pracy z grafiką warto zawsze zadać sobie pytanie: czy efekt polega na zmianie rozkładu jasności, na odwróceniu kolorów, czy na twardym podziale na dwa poziomy? Jeśli widzisz brak półtonów i ostre granice, praktycznie zawsze chodzi o progowanie, które zostało wskazane jako poprawna funkcja.