Pytanie 1
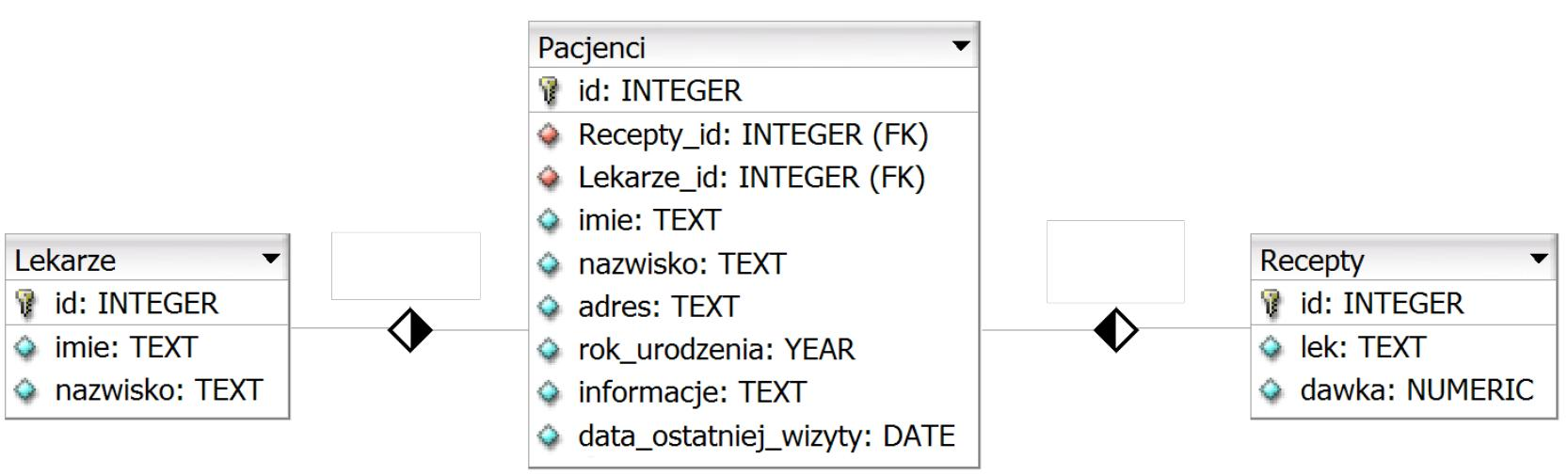
W językach programowania o układzie strukturalnym, aby przechować dane o 50 uczniach (ich imionach, nazwiskach oraz średniej ocen), konieczne jest zastosowanie
A. tablicy z 50 elementami o składowych strukturalnych
B. tablicy z 50 elementami o składowych typu łańcuchowego
C. struktury z 50 elementami o składowych typu tablicowego
D. klasy z 50 elementami typu tablicowego
Wybór niewłaściwych podejść do przechowywania informacji o uczniach często wynika z nieporozumienia dotyczącego struktury danych i ich właściwego zastosowania. Tworzenie struktury 50 elementów o składowych typu tablicowego sugeruje, że każdy element byłby tablicą, co nie odpowiada rzeczywistej naturze danych. Tego rodzaju podejście nie tylko komplikuje dostęp do informacji, ale również zwiększa ryzyko błędów w zarządzaniu danymi. Z kolei użycie tablicy 50 elementów o składowych łańcuchowych ogranicza nas do prostych typów danych, takich jak ciągi znaków, co uniemożliwia przechowywanie średniej ocen, która wymagałaby użycia innego typu danych, co narusza zasady typizacji. W przypadku klasy z 50 elementami typu tablicowego, problemem jest, że klasa powinna być używana do modelowania złożonych obiektów z zachowaniem, co nie jest konieczne w tym przypadku. Te nieścisłości pokazują typowe błędy myślowe związane z projektowaniem struktur danych. Kluczowym elementem skutecznego programowania jest zrozumienie, jak najlepiej reprezentować i przechowywać złożone dane, a także znajomość odpowiednich struktur, które umożliwią efektywne operacje na tych danych.