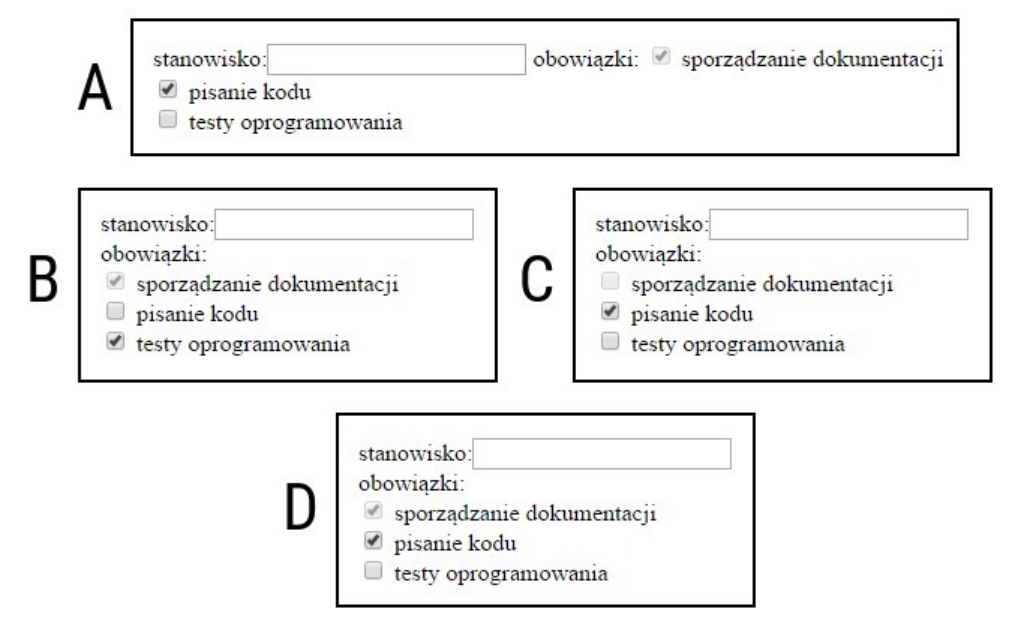
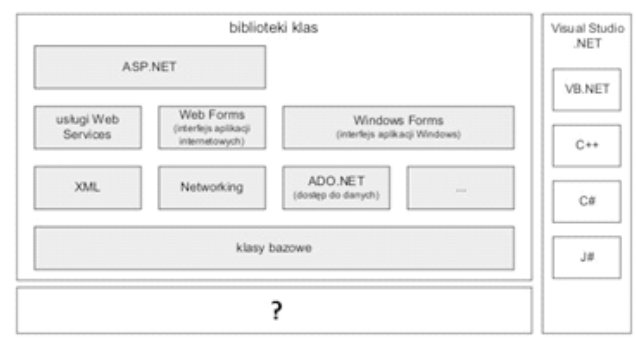
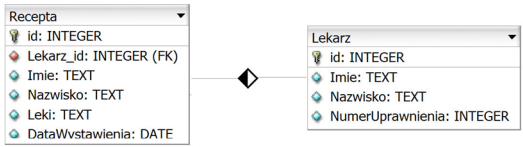
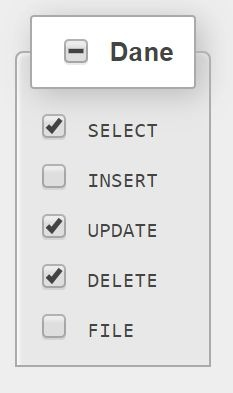
Pytanie 1
W językach programowania strukturalnego do przechowywania danych o 50 uczniach (ich imionach, nazwiskach, średniej ocen) należy zastosować
A. tablicę 50 elementów o składowych strukturalnych.
B. klasę 50 elementów typu tablicowego.
C. strukturę 50 elementów o składowych tablicowych.
D. tablicę 50 elementów o składowych typu łańcuchowego.
Odpowiedź wskazująca na użycie tablicy 50 elementów o składowych strukturalnych jest poprawna z kilku powodów. Po pierwsze, struktury (lub klasy) są idealnym rozwiązaniem do przechowywania złożonych danych, takich jak imiona, nazwiska i średnie oceny uczniów. Struktura pozwala na grupowanie tych składowych w jedną jednostkę, co zwiększa czytelność i organizację kodu. Na przykład, w języku C można zdefiniować strukturę 'Uczeń' z odpowiednimi polami, a następnie stworzyć tablicę, która pomieści 50 takich obiektów. W praktyce, struktury są szeroko stosowane w programowaniu, gdyż umożliwiają łatwe przekazywanie grup danych jako jednego obiektu, co jest zgodne z zasadami programowania obiektowego. Dodatkowo, korzystanie z tablicy struktur zamiast oddzielnych tablic dla każdego atrybutu ucznia minimalizuje ryzyko błędów związanych z synchronizacją danych i ułatwia manipulację danymi. W standardach programowania, szczególnie w kontekście zarządzania danymi, takie podejście jest uznawane za najlepszą praktykę, gdyż pozwala na spójną reprezentację oraz operowanie na danych.