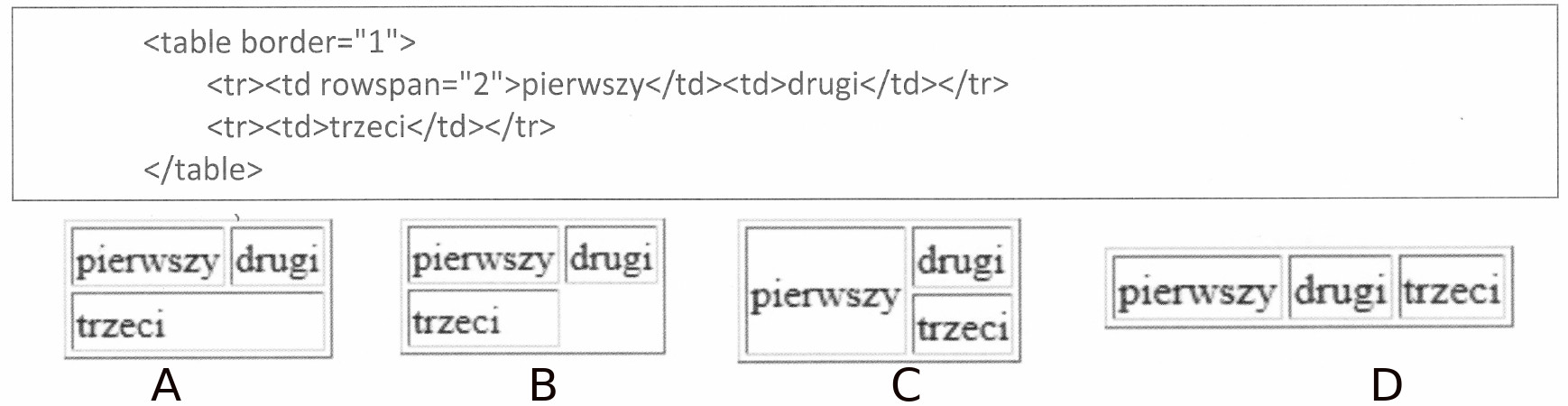
Pytanie 1
W HTML formularzu użyto elementu <input>. Pole, które się pojawi, ma pozwalać na wprowadzenie maksymalnie
| <input type="password" size="30" maxlength="20"> |
A. 20 znaków, które nie będą widoczne w polu tekstowym
B. 30 znaków, które będą widoczne podczas wpisywania
C. 20 znaków, które będą widoczne w trakcie wprowadzania
D. 30 znaków, które nie będą widoczne w polu tekstowym
Jeśli mówimy o znaczniku <input> w HTML, to dobrze jest wiedzieć, jak działają atrybuty typu maxlength i type. Atrybut maxlength pozwala ustawić maksymalną liczbę znaków w polu tekstowym. W polu typu password użytkownik może wpisać max 20 znaków, ale to, co widzisz, może być inne. Często myli się atrybut size z ograniczeniem liczby wprowadzanych znaków, ale tak naprawdę chodzi tylko o to, jak szerokie jest pole, więc nie zmienia jego funkcjonalności. Pole typu password ma na celu ukrycie wpisywanych znaków, co zazwyczaj oznacza, że to, co wpisujesz, zastąpione jest gwiazdkami lub kropkami, by nie było widać tego, co piszesz. Te rzeczy są ważne dla bezpieczeństwa aplikacji webowych. Ostatnio zauważyłem, że niektórzy mają problemy z rozumieniem tych atrybutów, co może prowadzić do błędów w obsłudze danych użytkowników i problemów z bezpieczeństwem.