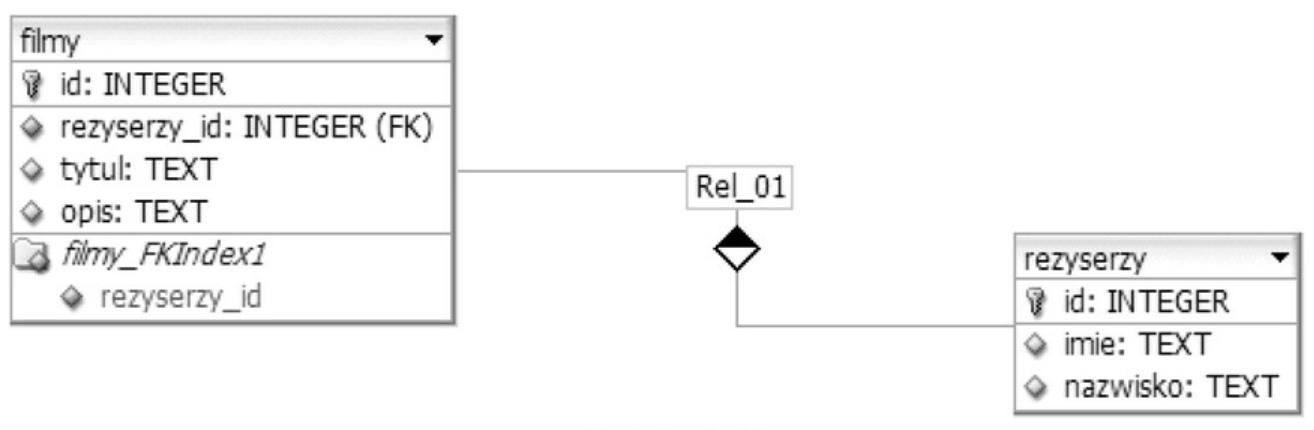
Pytanie 1
Na podstawie filmu wskaż, która cecha dodana do stylu CSS zamieni miejscami bloki aside i nav, pozostawiając w środku blok section?
A. nav { float: right; }
B. aside {float: left; }
C. nav { float: right; } section { float: right; }
D. nav { float: left; } aside { float: left; }
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Prawidłowa odpowiedź opiera się na tym, jak działają własności float w CSS i w jakiej kolejności przeglądarka renderuje elementy blokowe. Jeśli w dokumencie HTML kolejność znaczników to np. <aside>, potem <section>, a na końcu <nav>, to bez dodatkowego stylowania wszystkie trzy ustawią się pionowo, jeden pod drugim, w tej właśnie kolejności. Dodanie float zmienia sposób, w jaki elementy „odpływają” od normalnego przepływu dokumentu i jak układają się obok siebie. W stylu nav { float: right; } section { float: right; } sprawiamy, że zarówno nav, jak i section są przesuwane do prawej krawędzi kontenera, natomiast aside (bez float) pozostaje w normalnym przepływie, czyli z lewej strony. Ponieważ przeglądarka układa elementy w kolejności występowania w kodzie, najpierw wyrenderuje aside po lewej, potem section „odpłynie” w prawo, a na końcu nav też „odpłynie” w prawo, ustawiając się po prawej stronie, ale dalej od góry niż section. Efekt wizualny jest taki, że po lewej mamy aside, po prawej nav, a section ląduje między nimi, dokładnie tak jak było pokazane na filmie. Moim zdaniem to zadanie dobrze pokazuje, że przy floatach zawsze trzeba myśleć o trzech rzeczach naraz: kolejności elementów w HTML, kierunku „pływania” (left/right) oraz o tym, które elementy pozostawiamy w normalnym przepływie. W praktyce w nowoczesnych projektach częściej używa się flexboxa albo CSS Grid do takich układów, bo są czytelniejsze i mniej problematyczne. Przykładowo, zamiast kombinować z float, można by użyć display: flex; na kontenerze i ustawić order dla aside i nav. Float nadal jednak pojawia się w starszych layoutach i w zadaniach egzaminacyjnych, więc warto dobrze rozumieć jego zachowanie, choćby po to, żeby poprawnie modyfikować istniejące style lub naprawiać „rozjechane” układy w starszych projektach.
Prawidłowa odpowiedź opiera się na tym, jak działają własności float w CSS i w jakiej kolejności przeglądarka renderuje elementy blokowe. Jeśli w dokumencie HTML kolejność znaczników to np. <aside>, potem <section>, a na końcu <nav>, to bez dodatkowego stylowania wszystkie trzy ustawią się pionowo, jeden pod drugim, w tej właśnie kolejności. Dodanie float zmienia sposób, w jaki elementy „odpływają” od normalnego przepływu dokumentu i jak układają się obok siebie. W stylu nav { float: right; } section { float: right; } sprawiamy, że zarówno nav, jak i section są przesuwane do prawej krawędzi kontenera, natomiast aside (bez float) pozostaje w normalnym przepływie, czyli z lewej strony. Ponieważ przeglądarka układa elementy w kolejności występowania w kodzie, najpierw wyrenderuje aside po lewej, potem section „odpłynie” w prawo, a na końcu nav też „odpłynie” w prawo, ustawiając się po prawej stronie, ale dalej od góry niż section. Efekt wizualny jest taki, że po lewej mamy aside, po prawej nav, a section ląduje między nimi, dokładnie tak jak było pokazane na filmie. Moim zdaniem to zadanie dobrze pokazuje, że przy floatach zawsze trzeba myśleć o trzech rzeczach naraz: kolejności elementów w HTML, kierunku „pływania” (left/right) oraz o tym, które elementy pozostawiamy w normalnym przepływie. W praktyce w nowoczesnych projektach częściej używa się flexboxa albo CSS Grid do takich układów, bo są czytelniejsze i mniej problematyczne. Przykładowo, zamiast kombinować z float, można by użyć display: flex; na kontenerze i ustawić order dla aside i nav. Float nadal jednak pojawia się w starszych layoutach i w zadaniach egzaminacyjnych, więc warto dobrze rozumieć jego zachowanie, choćby po to, żeby poprawnie modyfikować istniejące style lub naprawiać „rozjechane” układy w starszych projektach.