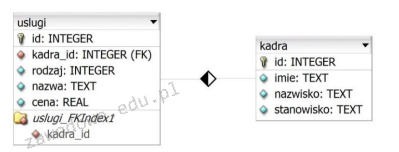
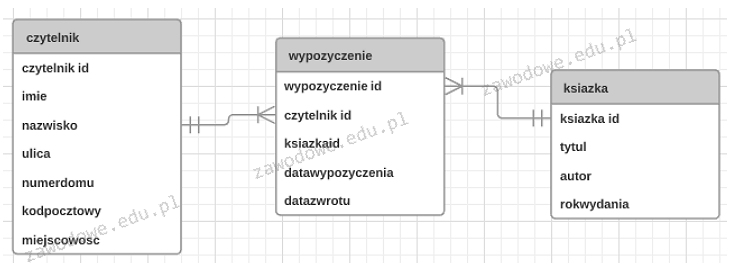
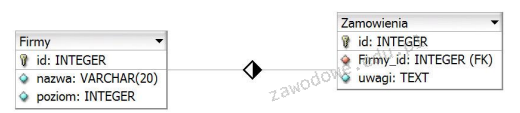
Pytanie 1
Które polecenie SQL usunie bazę danych o nazwie firma?
A.
DROP firma;
B.
ALTER firma DROP DATABASE;
C.
ALTER firma DROP;
D.
DROP DATABASE firma;
Całą bazę danych usuwa polecenie
DROP DATABASE <nazwa>, więc DROP DATABASE firma; skasuje bazę firma wraz z całą zawartością. Dlatego poprawne jest DROP DATABASE firma;.