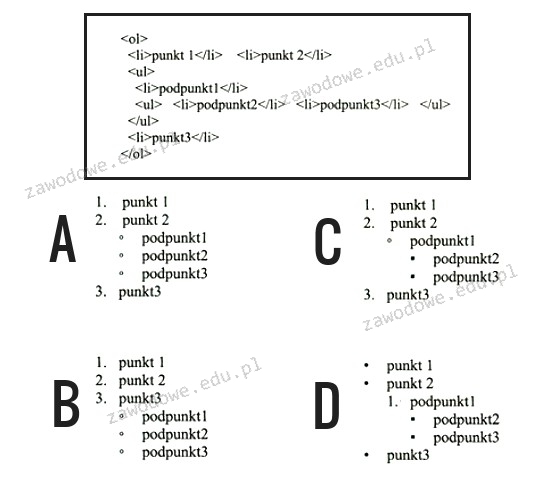
Pytanie 1
Który z poniższych kodów XHTML sformatuje tekst zgodnie z podanym przykładem?
Ala ma kota
a kot ma Alę
A. <p>Ala ma <b>kota <br /> a <i>kot</i> ma Alę</p>
B. <p>Ala ma <b>kota</b> <br/> a <b>kot</b> ma Alę</p>
C. <p>Ala ma <b>kota</i><br/> a <b>kot</b> ma Alę</p>
D. <p>Ala ma <b>kota</b> <br/> a <i>kot</i> ma Alę</p>
Odpowiedź <p>Ala ma <b>kota</b> <br/> a <i>kot</i> ma Alę</p> jest poprawna, ponieważ zgodnie z zasadami XHTML, użycie znaczników <b> i <i> do formatowania tekstu jest odpowiednie; <b> stosowany jest do wyróżniania tekstu pogrubionego, a <i> do kursywy. W tej odpowiedzi zastosowano również poprawny znacznik <br/>, który jest samodzielnym znacznikiem i nie wymaga zamknięcia w parze. Zgodnie z dobrymi praktykami, kod XHTML powinien być poprawnie sformatowany, a każdy otwierający znacznik powinien mieć odpowiadający mu zamykający znacznik, chyba że jest to znacznik samodzielny, jak <br/>. Warto zaznaczyć, że XHTML wymaga również, aby wszystkie atrybuty były zapisane w formacie małych liter, co zostało spełnione w tej odpowiedzi. Przykład zastosowania tej wiedzy można znaleźć w tworzeniu stron internetowych, gdzie poprawne sformatowanie kodu HTML lub XHTML jest kluczowe dla prawidłowego wyświetlania treści w przeglądarkach.