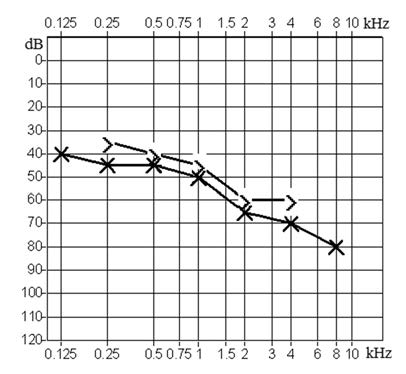
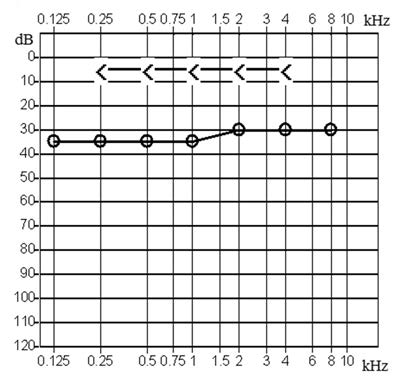
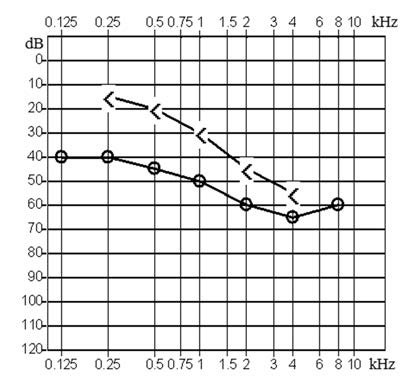
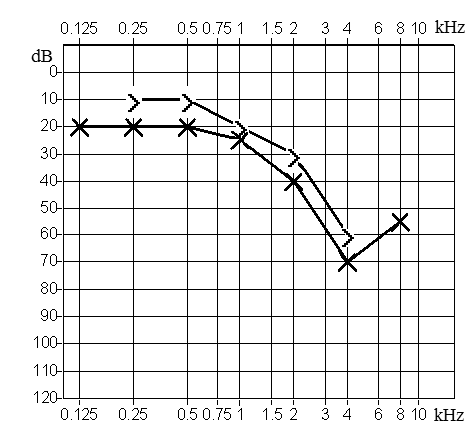
Pytanie 1
Podczas przetwarzania analogowo-cyfrowego w aparatach słuchowych, chcąc uniknąć błędu próbkowania, należy przyjąć częstotliwość próbkowania
A. równą dolnej składowej częstotliwości w sygnale.
B. przynajmniej dwa razy większą od górnej składowej częstotliwości w sygnale.
C. przynajmniej dwa razy mniejszą od górnej składowej częstotliwości w sygnale.
D. równą górnej składowej częstotliwości w sygnale.
Kluczowy błąd, który często się tu pojawia, polega na myleniu „częstotliwości występujących w sygnale” z „częstotliwością próbkowania”. Intuicyjnie ktoś może pomyśleć: skoro w sygnale mam składowe do pewnej górnej częstotliwości, to wystarczy próbkuję z taką samą częstotliwością albo nawet mniejszą. Niestety fizyka i matematyka sygnałów są tu dość bezlitosne. Jeżeli częstotliwość próbkowania jest równa górnej składowej częstotliwości, to próbki wychodzą tak rzadko, że sygnał sinusoidalny może być odwzorowany np. tylko dwoma punktami na okres, albo wręcz w taki sposób, że po rekonstrukcji wygląda jak sygnał o zupełnie innej częstotliwości. To jest właśnie aliasing – nakładanie się widm i mylenie wysokich częstotliwości z niższymi. Jeszcze gorzej jest, gdy częstotliwość próbkowania jest mniejsza od górnej składowej częstotliwości. Wtedy duża część informacji o sygnale po prostu ginie, a w widmie odtworzonym z próbek pojawiają się fałszywe składowe. W kontekście aparatów słuchowych oznaczałoby to zniekształconą mowę, nienaturalne barwy dźwięku, a nawet artefakty, które użytkownik mógłby odbierać jako nieprzyjemne „piski” lub „ćwierki”. Założenie, że wystarczy częstotliwość próbkowania równa dolnej składowej częstotliwości w sygnale, wynika z całkowitego niezrozumienia, co ogranicza pasmo – dolna składowa nie ma tu praktycznie znaczenia, bo to najwyższa częstotliwość determinuje minimalne wymagania na próbkowanie. Z kolei pomysł, żeby przyjąć częstotliwość próbkowania przynajmniej dwa razy mniejszą od górnej składowej, jest już całkowicie sprzeczny z twierdzeniem Nyquista-Shannona – to dokładnie sytuacja gwarantująca masywny aliasing. W prawidłowym podejściu zawsze patrzymy na najwyższą istotną składową sygnału (np. najwyższe użyteczne częstotliwości mowy i szumów środowiskowych, które chcemy kontrolować) i ustawiamy częstotliwość próbkowania co najmniej dwa razy wyżej, a w praktyce z pewnym zapasem. Dzięki temu cyfrowe algorytmy w aparatach słuchowych – kompresja, redukcja hałasu, kierunkowość mikrofonów, zarządzanie sprzężeniem zwrotnym – mają wiarygodne dane i mogą działać stabilnie oraz przewidywalnie. Moim zdaniem warto to traktować jako absolutną podstawę myślenia o każdym systemie audio, nie tylko o aparatach słuchowych.