Pytanie 1
Zaprezentowana linia kodu w języku PHP ma na celu
define("OSOBA", "Anna Kowalska");
A. porównać dwa ciągi znaków
B. przypisać dwie wartości do tablicy
C. zdefiniować stałą o nazwie OSOBA
D. ustalić wartość dla zmiennej $OSOBA
Odpowiedź "zdefiniować stałą o nazwie OSOBA" jest prawidłowa, ponieważ linia kodu define("OSOBA", "Anna Kowalska"); w języku PHP służy do tworzenia stałej. Stała to wartość, która nie zmienia się w trakcie działania programu. W tym przypadku, stała o nazwie OSOBA jest przypisywana do wartości "Anna Kowalska". Użycie stałych jest uważane za dobrą praktykę programistyczną, ponieważ pozwala na zdefiniowanie wartości, które mają być używane w różnych częściach aplikacji, co zwiększa czytelność i ułatwia zarządzanie kodem. Przykładem zastosowania stałych może być przechowywanie kluczy API, które nie powinny być zmieniane w trakcie działania aplikacji. Ponadto, korzystanie ze stałych może poprawić wydajność, gdyż PHP nie musi za każdym razem przeprowadzać operacji przypisania. Warto również zauważyć, że stałe w PHP są globalne i mogą być używane w dowolnym miejscu w kodzie, co czyni je bardzo użytecznymi w dużych projektach. Właściwe definiowanie i użycie stałych jest kluczowe dla utrzymania porządku i spójności w projekcie, co jest zgodne z ogólnie uznawanymi standardami programowania.
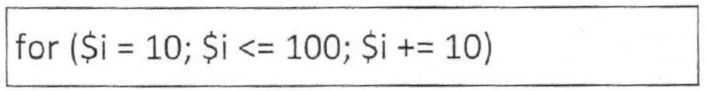
 ```
```

