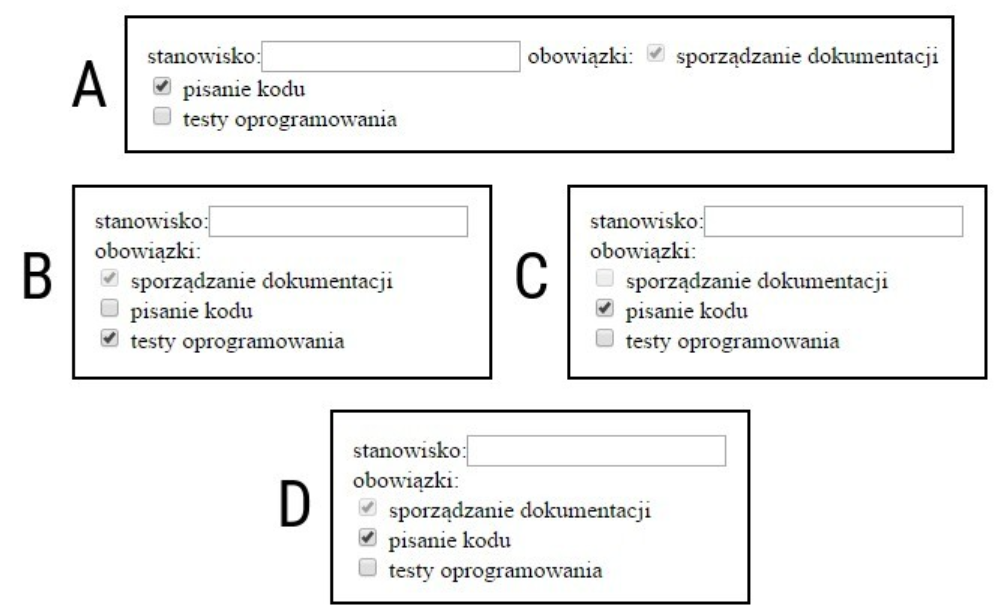
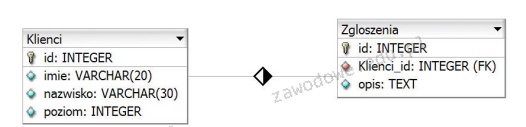
Pytanie 1
Jakie polecenie pozwala na kontrolowanie oraz optymalizację bazy danych?
A. mysqlimport
B. mysqlshow
C. mysqldump
D. mysqlcheck
Odpowiedzi takie jak 'mysqlshow', 'mysqldump' i 'mysqlimport' są mylące, ponieważ nie pełnią roli narzędzi do sprawdzania i optymalizacji bazy danych. Narzędzie mysqlshow służy jedynie do wyświetlania informacji o bazach danych i tabelach, co może być użyteczne do monitorowania istniejących struktur, ale nie wpływa na ich integralność ani wydajność. Z kolei mysqldump jest wykorzystywane do tworzenia zrzutów danych z bazy, co jest kluczowe dla backupów, ale nie ma żadnych funkcji związanych z optymalizacją czy konserwacją. Wreszcie, mysqlimport jest narzędziem do importowania danych z plików zewnętrznych do bazy danych, a więc również nie odnosi się do kwestii sprawdzania czy optymalizacji. Wybierając te odpowiedzi, można dojść do błędnych wniosków, sądząc, że jedno narzędzie może pełnić wiele funkcji, podczas gdy każde z wymienionych narzędzi ma swoje specyficzne zadania. Zrozumienie różnicy między tymi narzędziami jest kluczowe dla efektywnego zarządzania bazami danych oraz stosowania najlepszych praktyk w ich administracji.