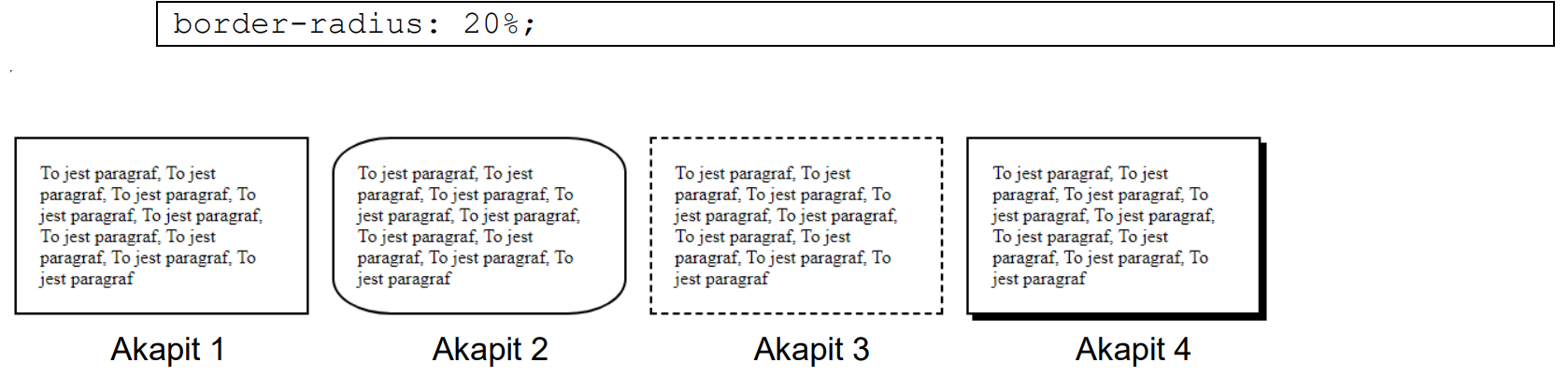
Pytanie 1
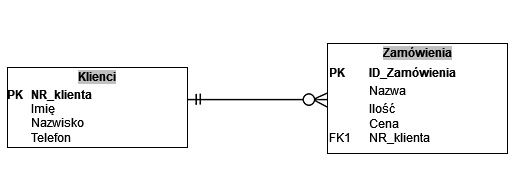
Na przedstawionym diagramie ER zapis FK1 oznacza
A. klucz podstawowy.
B. relację 1:1.
C. klucz obcy.
D. relację 1:N.
Skrót FK1 na diagramie ER oznacza klucz obcy (ang. foreign key) i jest to dokładnie to, co powinno łączyć tabelę Zamówienia z tabelą Klienci. W relacyjnych bazach danych klucz obcy to atrybut lub zestaw atrybutów, który wskazuje na klucz podstawowy w innej tabeli. Dzięki temu baza danych wie, że konkretne zamówienie należy do konkretnego klienta. W twoim diagramie pole NR_klienta w tabeli Zamówienia jest oznaczone jako FK1, czyli jest kluczem obcym odwołującym się do NR_klienta będącego kluczem podstawowym (PK) w tabeli Klienci. To jest klasyczny przykład relacji 1:N – jeden klient może mieć wiele zamówień, a każde zamówienie jest powiązane z dokładnie jednym klientem. W praktyce, w SQL, taka relacja jest definiowana mniej więcej tak: `FOREIGN KEY (NR_klienta) REFERENCES Klienci(NR_klienta)`. Taka definicja pozwala silnikowi bazy danych pilnować spójności referencyjnej, czyli np. nie pozwoli wstawić zamówienia z numerem klienta, który nie istnieje w tabeli Klienci, ani usunąć klienta, do którego wciąż istnieją zamówienia (chyba że jawnie zdefiniujemy CASCADE). Z mojego doświadczenia poprawne używanie kluczy obcych bardzo upraszcza później raportowanie, łączenie tabel w zapytaniach JOIN i ogólnie utrzymanie porządku w bazie. W modelowaniu ER oznaczenie FK wraz z numerem (FK1, FK2 itd.) to po prostu sposób na jednoznaczne nazwanie konkretnych kluczy obcych, gdy w systemie jest ich więcej. W dobrze zaprojektowanych bazach danych zawsze warto jawnie definiować foreign key, zamiast tylko „ufać”, że aplikacja będzie podawała poprawne dane – to jest po prostu dobra praktyka i standard w profesjonalnych projektach.