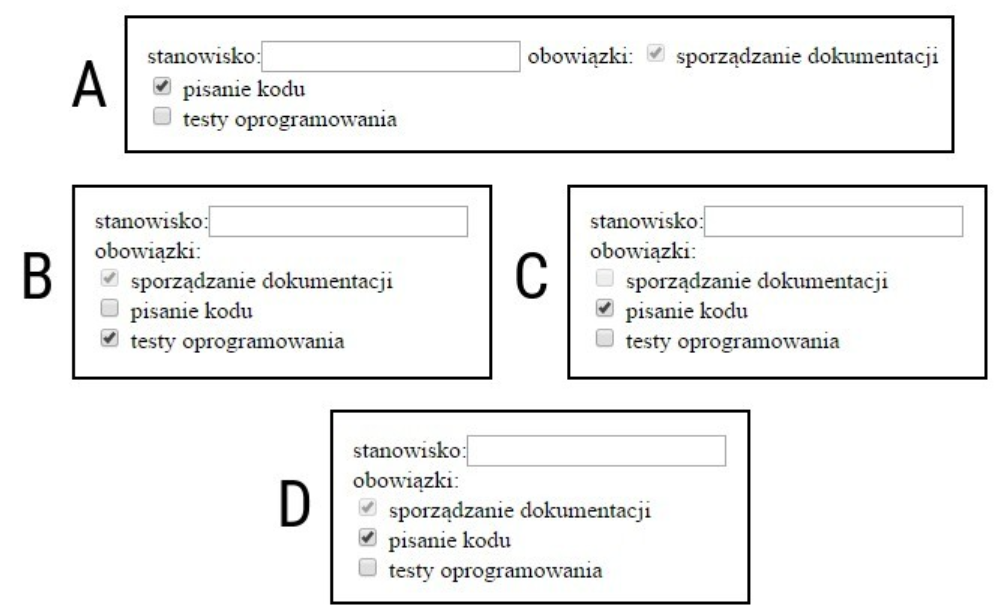
Pytanie 1
W zaprezentowanym fragmencie algorytmu wykorzystano
A. jedną pętlę
B. jeden blok decyzyjny
C. dwie pętle
D. trzy bloki operacyjne (procesy)
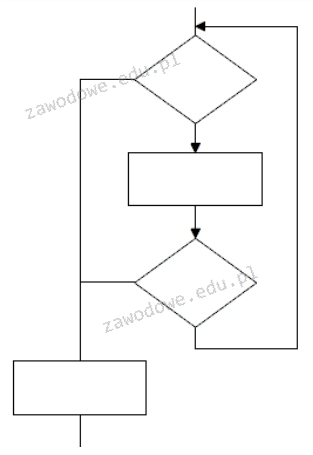
Na tym diagramie widać jedną pętlę, co jest dość ważne w programowaniu. Pętla pozwala na powtarzanie pewnych działań, aż spełni się jakiś warunek. Tu mamy blok decyzyjny, który mówi, czy proces ma trwać, czy się zakończyć. To dość powszechnie używane podejście, zwłaszcza w algorytmach, jak na przykład sortowanie czy obróbka danych. Warto zwrócić uwagę, by dobrze zrozumieć, jak działają pętle, szczególnie te oparte na warunkach, jak while czy for. Pozwoli to uniknąć problemów z niekończącymi się pętlami, które mogą sprawić, że program przestanie działać. Z mojego doświadczenia, ogarnać te struktury to kluczowy skill dla każdego, kto chce działać w IT.