Pytanie 1
Z przedstawionych tabel Artykuly i Autorzy należy wybrać jedynie nazwiska autorów i tytuły ich artykułów, które zostały ocenione na 5. Kwerenda wybierająca te dane ma postać
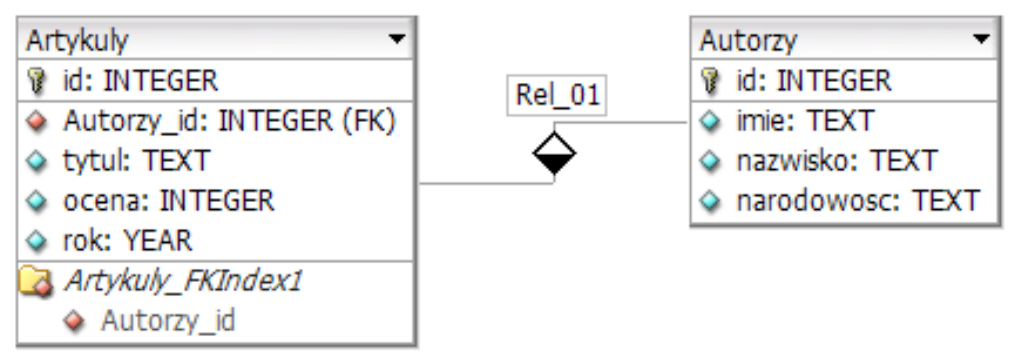
A. SELECT nazwisko, tytul FROM autorzy, artykuly WHERE ocena == 5;
B. SELECT nazwisko, tytul FROM autorzy JOIN artykuly ON autorzy.id = autorzy_id WHERE ocena = 5;
C. SELECT nazwisko, tytul FROM autorzy JOIN artykuly ON autorzy.id = autorzy_id;
D. SELECT nazwisko, tytul FROM autorzy JOIN artykuly ON autorzy.id = artykuly.id;
Gratulacje! Wybrałeś poprawne zapytanie SQL, które dokładnie odpowiada na postawione pytanie. Zapytanie 'SELECT nazwisko, tytul FROM autorzy JOIN artykuly ON autorzy.id = autorzy_id WHERE ocena = 5;' jest prawidłowe, bo łączy dwie tabele 'autorzy' i 'artykuly' za pomocą klucza obcego 'autorzy_id' w tabeli 'artykuly'. Dzięki temu uzyskujemy dostęp do nazwisk autorów i tytułów artykułów. Dodatkowo, część 'WHERE ocena = 5' filtruje wyniki tak, aby wyświetlane były tylko te rekordy, gdzie ocena wynosi 5. To jest kluczowy element, który pozwala nam skupić się tylko na tych danych, które są istotne dla pytania. W praktyce, tego typu zapytania pomagają nam w analizie wydajności autorów i jakości artykułów, co jest niezwykle ważne w branży wydawniczej.