Pytanie 1
Wskaż fragment kodu, który stanowi realizację przedstawionego algorytmu w języku C++.
Kod 1do { suma = suma + i; } while (suma <= liczba); cout << suma; | Kod 2if (suma <= liczba) { suma = suma + i; i++; } else cout << suma; |
Kod 3for (i = suma; i <= liczba; i++) suma = suma + i; else cout << suma; | Kod 4while (suma <= liczba) { suma = suma + i; i++; } cout << suma; |
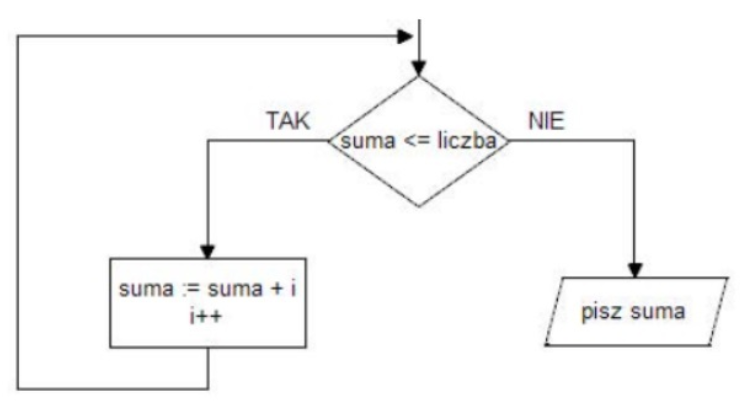
A. kod 4
B. kod 2
C. kod 1
D. kod 3
Wybrałeś fragment kodu, który faktycznie odwzorowuje logikę schematu blokowego: najpierw sprawdzamy warunek suma <= liczba, a dopiero gdy jest spełniony, wchodzimy do pętli, dodajemy i do zmiennej suma, inkrementujemy licznik i i wracamy do ponownego sprawdzenia warunku. To jest klasyczne zastosowanie pętli while, czyli sytuacji, kiedy nie znamy liczby iteracji z góry, ale wiemy, kiedy mamy skończyć – w tym wypadku, gdy suma przekroczy wartość graniczną liczba. Z mojego doświadczenia właśnie tak wygląda typowy fragment kodu sumujący kolejne liczby naturalne, dopóki nie zostanie osiągnięty limit. Ważne jest też to, że instrukcja wypisania wyniku znajduje się dopiero za pętlą, więc zostanie wykonana dokładnie raz, po zakończeniu obliczeń, co idealnie zgadza się z blokiem pisz suma na schemacie. W dobrych praktykach programistycznych zawsze pilnujemy, żeby warunek pętli dokładnie odpowiadał opisowi w algorytmie, a modyfikacja zmiennych sterujących, takich jak suma i i, była wykonywana wewnątrz pętli w spójny sposób. Taka konstrukcja jest potem łatwa w utrzymaniu, przeniesieniu do innych języków czy modyfikacji, na przykład można bez problemu zmienić warunek na suma < liczba albo dodać dodatkowe sprawdzenie, czy i nie rośnie za szybko. W praktycznych projektach, np. przy obliczaniu sum kontrolnych, limitów budżetowych, punktów gracza w grze, dokładnie taki wzorzec while warunek, obliczenia, inkrementacja, wypisz wynik pojawia się naprawdę często.