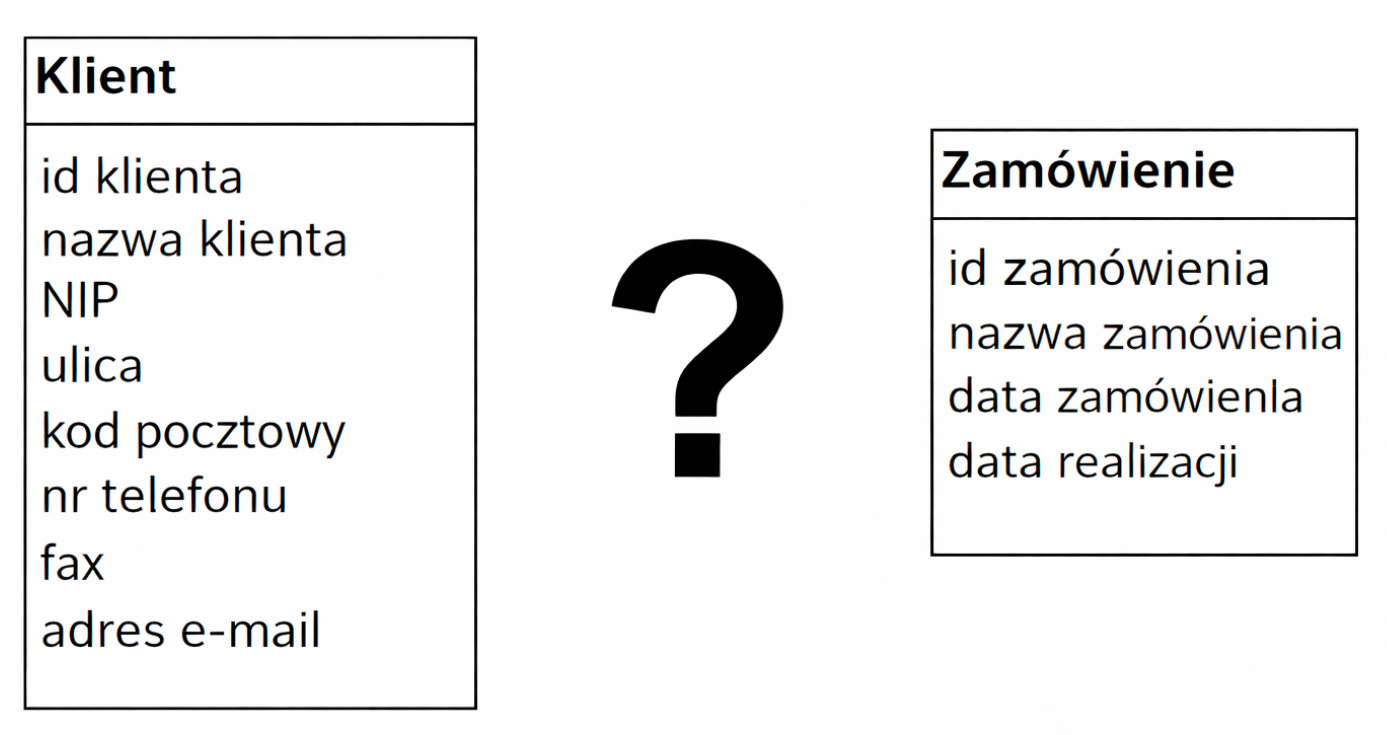
Pytanie 1
Używając polecenia BACKUP LOG w MS SQL Server, można
A. wykonać całkowitą kopię zapasową
B. przeglądać komunikaty wygenerowane w trakcie tworzenia kopii
C. wykonać kopię zapasową dziennika transakcji
D. połączyć się z kopią zapasową
Polecenie BACKUP LOG w MS SQL Server jest używane do wykonywania kopii bezpieczeństwa dziennika transakcyjnego bazy danych. Dziennik transakcyjny jest kluczowym komponentem, który rejestruje wszystkie zmiany w bazie danych, co pozwala na ich odtworzenie w przypadku awarii lub błędów. Regularne tworzenie kopii zapasowych dziennika transakcyjnego jest istotne, ponieważ umożliwia przywracanie bazy danych do stanu sprzed określonego zdarzenia. Na przykład, po wykonaniu BACKUP LOG można przywrócić bazę danych do stanu sprzed ostatniej transakcji, co może być bardzo przydatne w sytuacjach awaryjnych, takich jak przypadkowe usunięcie danych. Standardy takie jak RPO (Recovery Point Objective) i RTO (Recovery Time Objective) wskazują na znaczenie systematycznego tworzenia kopii zapasowych dzienników transakcyjnych w strategiach zarządzania danymi. Aby wykonać kopię zapasową dziennika transakcyjnego, używa się składni: BACKUP LOG [nazwa_bazy_danych] TO DISK = 'ścieżka_do_pliku.bak'.