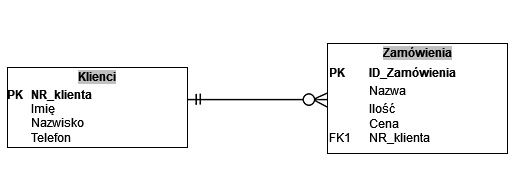
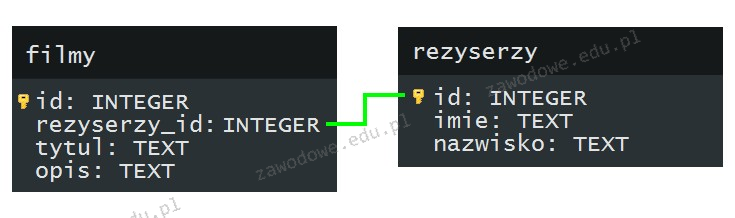
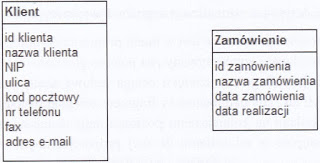
Pytanie 1
DELETE FROM Pracownicy ORDER BY rok_urodzenia LIMIT 1;W wyniku wykonania powyższego zapytania SQL zostanie:
A. usunięty rekord z danymi pracownika, który miał wpisaną datę urodzenia.
B. usunięta tabela Pracownicy.
C. usunięta kolumna rok_urodzenia z tabeli Pracownicy.
D. usunięty rekord najstarszego pracownika.
Poprawnie – to polecenie SQL usuwa dokładnie jeden rekord, i to taki, który odpowiada najstarszemu pracownikowi w tabeli. Kluczowe są tu dwie rzeczy: klauzula ORDER BY oraz LIMIT 1. Najpierw baza danych sortuje wiersze z tabeli Pracownicy po kolumnie rok_urodzenia rosnąco, czyli od najstarszego do najmłodszego (mniejszy rok urodzenia = starsza osoba). Dopiero na tak posortowanym zbiorze polecenie DELETE z LIMIT 1 usuwa pierwszy rekord z góry, czyli właśnie najstarszego pracownika. Warto zauważyć, że taka składnia (DELETE ... ORDER BY ... LIMIT ...) jest charakterystyczna m.in. dla MySQL i MariaDB. W standardowym SQL nie zawsze można użyć ORDER BY bezpośrednio w DELETE, ale w praktyce, w aplikacjach webowych, bardzo często pracuje się właśnie na tych silnikach, więc to rozwiązanie jest jak najbardziej realne. W innych systemach (np. PostgreSQL) podobny efekt robi się przez podzapytanie lub CTE. Moim zdaniem to jest bardzo przydatny wzorzec, gdy chcemy usuwać „najstarsze” lub „najmłodsze” rekordy, np. najstarszy log systemowy, najstarsze zamówienie w statusie roboczym, najstarszy wpis w kolejce zadań. Ważna dobra praktyka: takie operacje powinny opierać się na jednoznacznym kryterium sortowania (np. rok_urodzenia + id), żeby uniknąć sytuacji, że przy tych samych wartościach pola baza wybierze losowo któryś rekord. W projektach produkcyjnych często dodaje się dodatkową kolumnę typu data_utworzenia albo używa klucza głównego w ORDER BY, żeby zachować deterministyczne zachowanie. Zwróć też uwagę, że DELETE operuje na wierszach (rekordach), a nie na strukturze tabeli. Do usuwania kolumn służy ALTER TABLE, a do kasowania całej tabeli – DROP TABLE. To rozróżnienie jest absolutna podstawa pracy z SQL w każdej większej aplikacji.