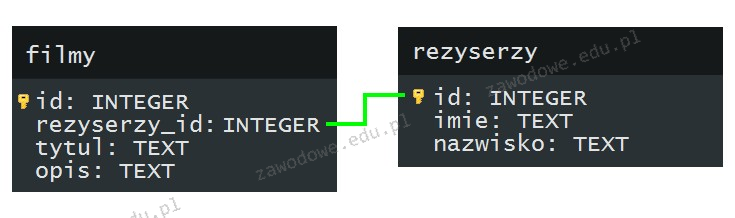
Pytanie 1
Funkcją zaprezentowanego kodu PHP jest napełnienie tablicy $tab 10 losowymi liczbami z przedziału od -100 do 100, a następnie wypisanie liczb ujemnych. Kod prezentuje się następująco:
$tab = array(); for ($i = 0; $i < 10; $i++) { $tab[$i] = rand(-100, 100); } foreach ($tab as $x) { if ($x < 0) echo "$x "; }
A. 100 losowymi liczbami, a następnie wypisanie liczb dodatnich
B. kolejnymi liczbami od -100 do 100 oraz wypisanie liczb ujemnych
C. 10 losowymi wartościami, a następnie wypisanie liczb ujemnych
D. kolejnymi liczbami od 0 do 9 i ich wyświetlenie
Interpretacja kodu pod kątem generowania liczb od -100 do 100 i ich wypisywania jest błędna ze względu na niewłaściwe zrozumienie funkcji rand oraz struktury pętli. Kod generuje dziesięć losowych wartości, ale nie wypisuje wszystkich liczb z zakresu, a jedynie ujemne liczby z wylosowanego zbioru. Podobnie, przypuszczenie, że kod wypełnia tablicę kolejnymi liczbami od 0 do 9 i je wypisuje, wynika z błędnego pojmowania mechanizmu inkrementacji zmiennej i oraz przypisania losowych wartości w tablicy. Wreszcie, myśl, że kod wypełnia 100 losowymi wartościami, jest błędna, ponieważ struktura pętli została ustawiona na dziesięć iteracji i nie ma elementu, który by sugerował generowanie aż 100 elementów. Ważne jest, aby dokładnie przeanalizować strukturę kodu i zrozumieć, jakie operacje są wykonywane w ramach każdej pętli oraz jakie wartości są faktycznie manipulowane. Zrozumienie funkcji rand i poprawne rozpoznanie zakresu liczby iteracji jest kluczowe w analizie i interpretacji kodu w językach programowania takich jak PHP. Poprawne zrozumienie logiki warunkowej if umożliwia prawidłową identyfikację, jakie elementy są wypisywane na końcu procesu, co jest istotne w wielu praktycznych zastosowaniach programistycznych.