Pytanie 1
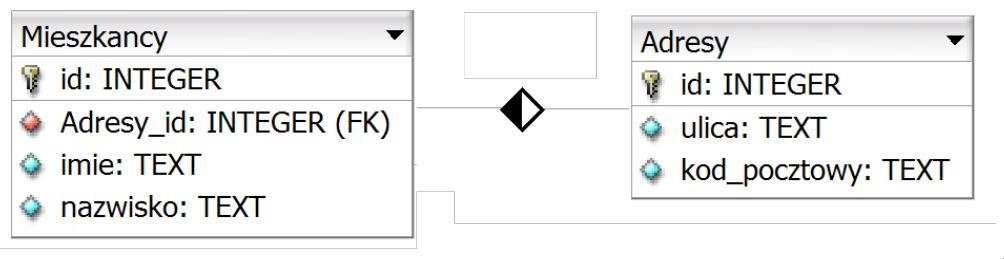
Baza danych 6-letniej szkoły podstawowej zawiera tabelę uczniowie z kolumnami: imie, nazwisko, klasa. Wszyscy uczniowie w klasach 1 - 5 zaliczyli do następnej klasy. Aby zwiększyć wartość w kolumnie klasa o 1, należy wykorzystać następujące polecenie
A. UPDATE nazwisko, imie SET klasa=klasa+1 WHERE klasa>1 OR klasa<5;
B. SELECT nazwisko, imie FROM klasa=klasa+1 WHERE klasa>1 OR klasa<5;
C. UPDATE uczniowie SET klasa=klasa+1 WHERE klasa>=1 AND klasa<=5;
D. SELECT uczniowie FROM klasa=klasa+1 WHERE klasa>=1 AND klasa<=5;
Poprawna odpowiedź to 'UPDATE szkola SET klasa=klasa+1 WHERE klasa>=1 AND klasa<=5;'. To polecenie SQL jest zgodne z praktykami stosowanymi do aktualizacji danych w bazach danych. Funkcja UPDATE służy do modyfikacji istniejących rekordów w tabeli. W tym przypadku chcemy zwiększyć wartość w kolumnie 'klasa' dla wszystkich uczniów, którzy są obecnie w klasach od 1 do 5. Warunek 'WHERE klasa>=1 AND klasa<=5' zapewnia, że tylko uczniowie z tych klas zostaną zaktualizowani, co jest zgodne z logiką biznesową wskazującą, że wszyscy uczniowie klas 1-5 zdali do następnej klasy. Dzięki temu mamy pewność, że operacja jest przeprowadzana w bezpieczny sposób, minimalizując ryzyko błędów w danych. W praktyce, takie operacje są często stosowane, np. na koniec roku szkolnego, gdy uczniowie przechodzą do wyższej klasy. Ponadto, w kontekście najlepszych praktyk, ważne jest, aby przed wykonaniem operacji UPDATE przeprowadzić odpowiednie zabezpieczenia, takie jak tworzenie kopii zapasowych danych, aby uniknąć utraty informacji.