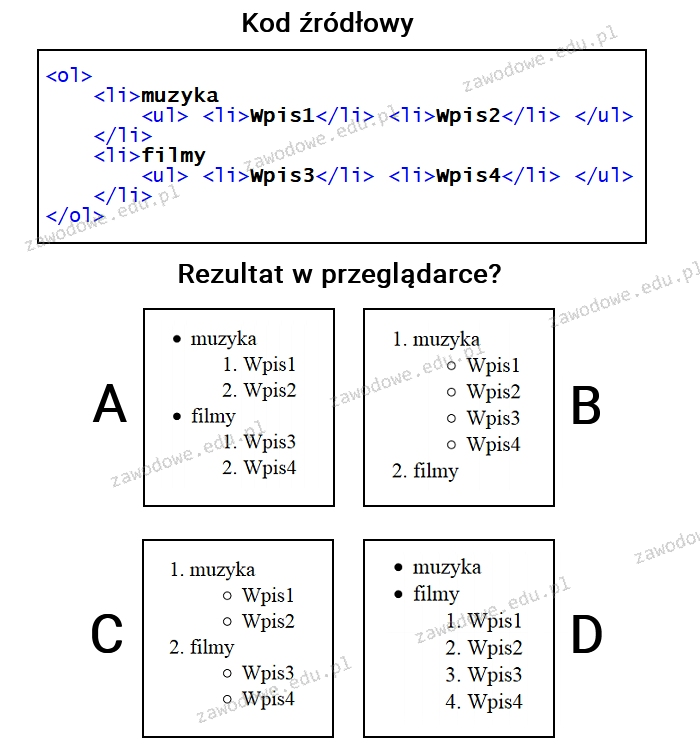
Pytanie 1
W kodzie HTML stworzono link do strony internetowej. Aby otworzyć tę stronę w nowym oknie lub zakładce przeglądarki, należy dodać do definicji linku atrybut
<a href="http://google.com" >strona Google</a>
A. rel = "external"
B. target = "_blank"
C. rel = "next"
D. target = "_parent"
Atrybut target w języku HTML służy do określenia, w jaki sposób ma otworzyć się dokument, do którego prowadzi odnośnik. Użycie wartości '_blank' dla atrybutu target jest standardowym sposobem na otwarcie nowej strony w nowym oknie lub zakładce przeglądarki. Przykład zastosowania to: <a href="http://google.com" target="_blank">strona Google</a>. Jest to niezwykle przydatne w kontekście UX, ponieważ pozwala użytkownikom na łatwe porównanie informacji bez utraty dostępu do oryginalnej strony. Warto również zauważyć, że użycie tego atrybutu jest zgodne z najlepszymi praktykami w tworzeniu stron internetowych, gdyż umożliwia użytkownikom zachowanie kontekstu przeglądania. W HTML5 atrybut target pozostaje wspierany, co czyni go istotnym elementem w projektowaniu interfejsów użytkownika. Oprócz '_blank' istnieją inne wartości, takie jak '_self', '_parent' i '_top', które również spełniają różne funkcje w zależności od potrzeb nawigacyjnych w aplikacji webowej.