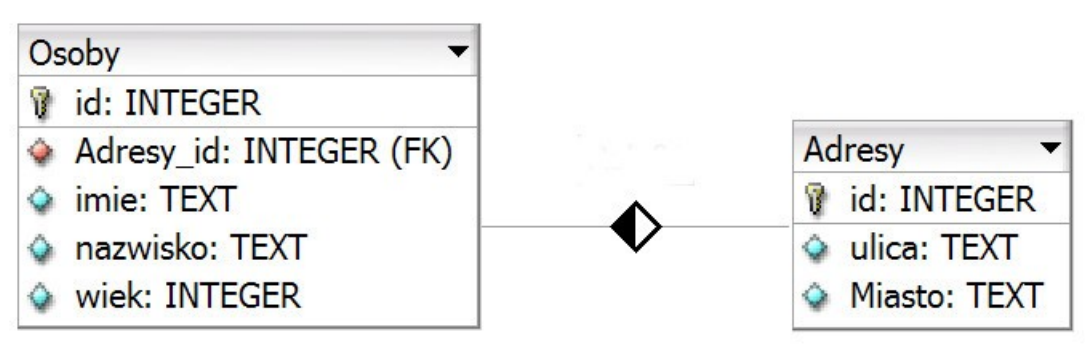
Pytanie 1
Aby przywrócić bazę danych MS SQL z archiwum, należy użyć polecenia
A. RESTORE DATABASE
B. REBACKUP DATABASE
C. SAVE DATABASE
D. DBCC CHECKDB
Pozostałe odpowiedzi nie są właściwe w kontekście przywracania bazy danych MS SQL z kopii bezpieczeństwa. DBCC CHECKDB jest narzędziem służącym do sprawdzania integralności bazy danych, ale nie ma zastosowania w procesie przywracania danych. To polecenie diagnostyczne pozwala na identyfikację uszkodzeń strukturalnych bazy danych oraz ich potencjalne naprawienie, co jest ważne, lecz nie dotyczy samego procesu przywracania. SAVE DATABASE nie jest uznawane za standardowe polecenie w MS SQL Server. Takie działanie nie istnieje w dokumentacji, co oznacza, że nie można go używać do wykonywania operacji na bazach danych. Ostatnia odpowiedź, REBACKUP DATABASE, również nie jest poprawna, ponieważ MS SQL Server nie posiada takiej komendy. W rzeczywistości, proces tworzenia kopii zapasowej danych realizuje się za pomocą polecenia BACKUP DATABASE, a nie REBACKUP. Każda z tych odpowiedzi ma swoje zastosowanie w pracy z bazami danych, ale w kontekście przywracania nie spełniają wymagań. Dlatego kluczowe jest zrozumienie roli polecenia RESTORE DATABASE w prawidłowym zarządzaniu bazami danych.