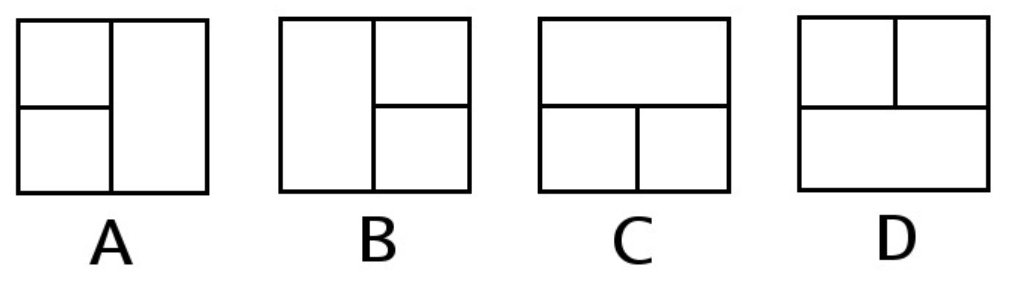
Pytanie 1
W języku JavaScript przedstawiona poniżej definicja jest definicją
var imiona=["Anna", "Jakub", "Iwona", "Krzysztof"];
A. tablicy.
B. klasy.
C. kolekcji.
D. obiektu.
W języku JavaScript definicja var imiona=["Anna", "Jakub", "Iwona", "Krzysztof"]; przedstawia tablicę, która jest jednym z fundamentalnych typów danych w tym języku. Tablice są używane do przechowywania zbiorów danych w sposób uporządkowany. W tym przypadku tablica imiona przechowuje cztery stringi, każdy reprezentujący imię. Wartością dodaną tablicy jest możliwość dostępu do poszczególnych elementów za pomocą indeksów, które zaczynają się od zera. Na przykład, imiona[0] zwróci \"Anna\", a imiona[1] zwróci \"Jakub\". W praktyce tablice są niezwykle przydatne w programowaniu, ponieważ pozwalają na łatwe zarządzanie i manipulację danymi. Dobrą praktyką jest używanie tablic do przechowywania związków danych, co umożliwia ich efektywne przetwarzanie i iterację za pomocą pętli, co zwiększa czytelność i organizację kodu. Warto również zaznaczyć, że tablice w JavaScript są obiektami, co daje dodatkowe możliwości manipulacji, takie jak metody tablicowe (np. push, pop, map, filter) do operacji na zbiorach danych. Poznanie i zrozumienie tablic jest kluczowe dla każdego programisty, ponieważ są one podstawą wielu algorytmów i struktur danych."