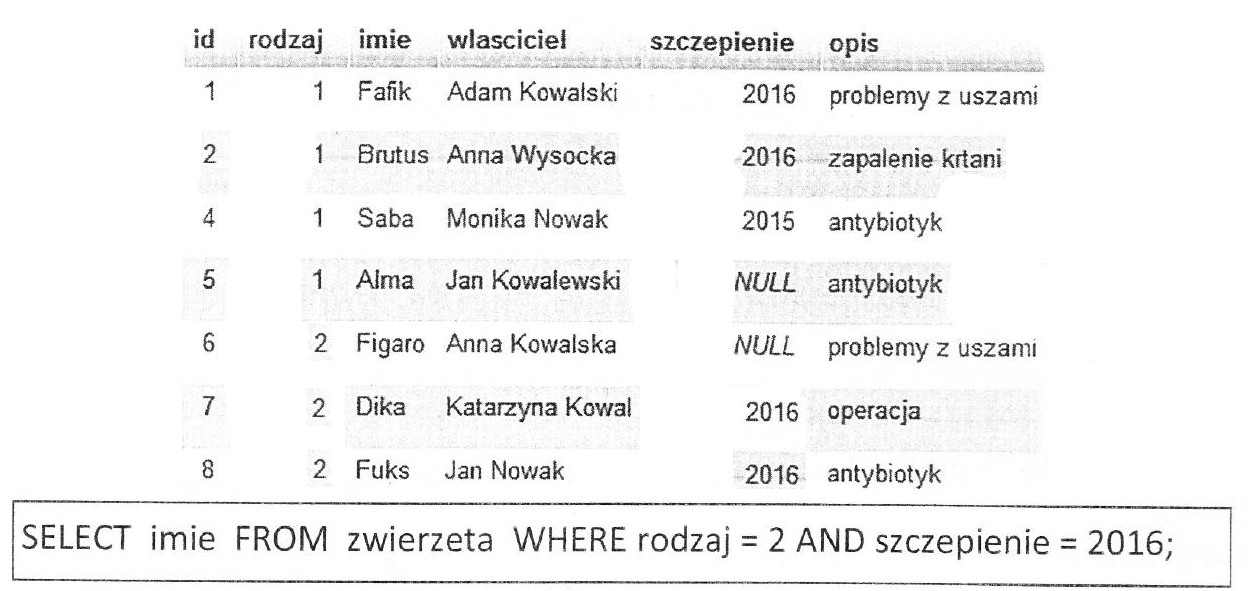
Pytanie 1
Jakie uprawnienia są konieczne do wykonania oraz przywrócenia kopii zapasowej bazy danych Microsoft SQL Server 2005 Express?
A. Administrator systemu
B. Security users
C. Users
D. Użytkownik lokalny
Aby wykonać i odtworzyć kopię zapasową bazy danych Microsoft SQL Server 2005 Express, wymagane jest posiadanie uprawnień administratora systemu. Administratorzy mają pełny dostęp do wszystkich funkcji i zasobów systemu, co jest kluczowe podczas zarządzania kopiami zapasowymi, które są niezbędne dla bezpieczeństwa i integralności danych. W kontekście SQL Server, administratorzy mogą korzystać z różnych narzędzi, takich jak SQL Server Management Studio (SSMS), aby tworzyć kopie zapasowe baz danych oraz przywracać je w razie potrzeby. Dobrą praktyką jest regularne tworzenie kopii zapasowych, co pozwala na minimalizację ryzyka utraty danych wskutek awarii systemu, błędów ludzkich czy ataków złośliwego oprogramowania. Ponadto, znajomość polityk przechowywania kopii zapasowych, takich jak ich rotacja i przechowywanie w bezpiecznych lokalizacjach, stanowi integralną część zarządzania danymi w organizacji. Warto również pamiętać o testowaniu procesów przywracania danych, aby upewnić się, że w sytuacji kryzysowej dostęp do informacji będzie możliwy w sposób szybki i efektywny.