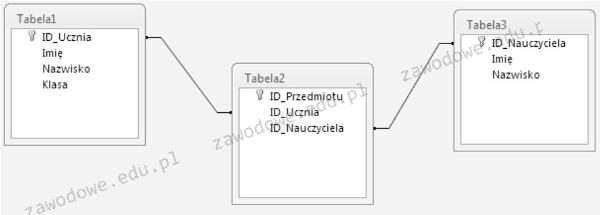
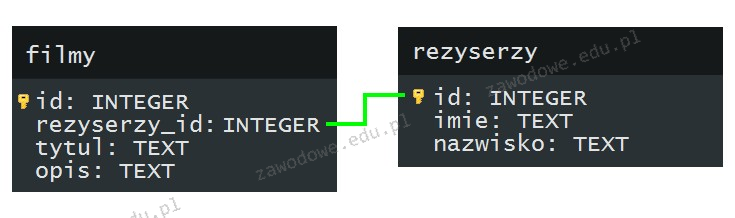
Pytanie 1
Aby aplikacja PHP mogła nawiązać połączenie z bazą danych, konieczne jest najpierw użycie funkcji o nazwie
A. mysqli_select_db
B. mysqli_connect
C. mysqli_create_db
D. mysqli_close
Funkcja mysqli_connect jest kluczowym elementem w procesie komunikacji aplikacji PHP z bazą danych. Jej głównym zadaniem jest nawiązanie połączenia z serwerem MySQL, co jest niezbędne, zanim jakiekolwiek operacje na danych mogą zostać przeprowadzone. Wywołując tę funkcję, należy podać odpowiednie parametry: nazwę hosta (zazwyczaj 'localhost'), nazwę użytkownika, hasło oraz nazwę bazy danych, z którą chcemy pracować. Na przykład: $conn = mysqli_connect('localhost', 'user', 'password', 'database');. Dobrą praktyką jest również sprawdzenie, czy połączenie zostało nawiązane poprawnie, co można zrobić za pomocą odpowiednich warunków. W przypadku ewentualnych błędów podczas nawiązywania połączenia, funkcja ta zwraca wartość false, co umożliwia dalsze działania naprawcze. Dodatkowo, w kontekście bezpieczeństwa, warto stosować techniki takie jak przygotowywanie zapytań (prepared statements), aby zminimalizować ryzyko ataków typu SQL Injection. Właściwe nawiązanie połączenia z bazą danych jest fundamentem każdej aplikacji webowej opartej na PHP.