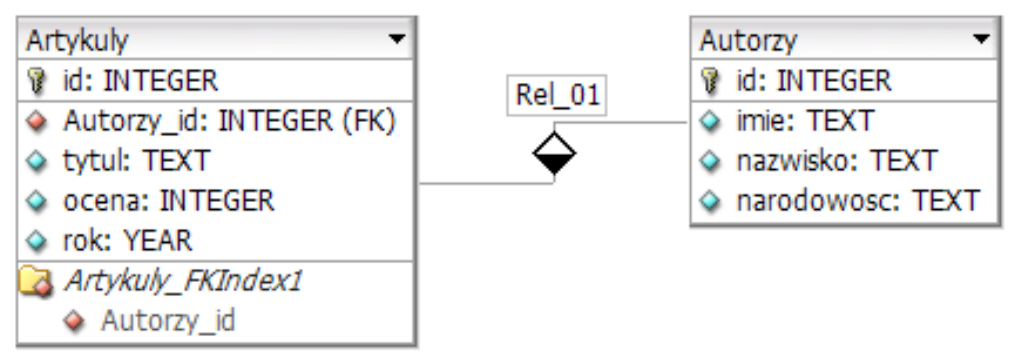
Pytanie 1
Kod programu wraz z komentarzami oraz opisem algorytmów i metod stanowi dokumentację
A. audiowizualną.
B. urzędową.
C. graficzną.
D. techniczną.
Poprawnie – mówimy tutaj o dokumentacji technicznej. Kod programu razem z komentarzami w kodzie, opisem algorytmów, struktur danych, interfejsów, sposobu działania poszczególnych modułów czy klas to właśnie klasyczny przykład dokumentacji technicznej. W branży IT przyjmuje się, że dokumentacja techniczna jest skierowana głównie do programistów, administratorów, czasem też architektów systemów, czyli osób, które będą rozwijać, utrzymywać lub integrować dany system. Nie jest to materiał marketingowy ani „urzędowy”, tylko coś, co ma pomóc zrozumieć jak system działa od środka. W praktyce dokumentacja techniczna obejmuje na przykład: komentarze w kodzie źródłowym (zgodne z konwencją danego języka, np. PHPDoc, JSDoc), opisy algorytmów w plikach README, wiki projektowe, diagramy UML, schematy przepływu danych, opisy endpointów API, a nawet instrukcje uruchomienia środowiska developerskiego. Moim zdaniem im lepiej zrobiona taka dokumentacja, tym łatwiej jest później komuś „wejść” w projekt bez zadawania dziesiątek pytań. Dobre praktyki mówią, żeby dokumentacja techniczna była aktualna, wersjonowana razem z kodem (np. w Git), a komentarze w kodzie nie powtarzały tego, co oczywiste, tylko wyjaśniały „dlaczego tak”, a nie „co robi ta linijka”. W projektach webowych dokumentacja techniczna opisuje na przykład, jak działa logika logowania użytkownika, jak są zrobione zapytania do bazy, jakie są ograniczenia wydajnościowe. To wszystko pozwala utrzymać spójność systemu i ułatwia debugowanie oraz rozwój nowych funkcji. Dlatego odpowiedź „techniczną” jest jak najbardziej zgodna z tym, jak branża rozumie dokumentację w kontekście programowania i algorytmów.