W PHP, aby przekierować użytkownika na inną stronę internetową, można użyć funkcji
A. upload();
B. header();
C. include();
D. require();
Funkcja header() w języku PHP służy do wysyłania nagłówków HTTP do przeglądarki użytkownika, co pozwala na przekierowanie go na inną stronę. Aby to zrobić, należy wywołać funkcję header() z odpowiednim argumentem, na przykład: header('Location: http://www.example.com');. To podejście jest zgodne z najlepszymi praktykami w programowaniu, ponieważ umożliwia natychmiastowe przekierowanie użytkownika przed jakimkolwiek innym wyjściem z skryptu. Ważne jest jednak, aby nie wysłać żadnych danych do przeglądarki przed wywołaniem header(), ponieważ PHP nie pozwala na modyfikację nagłówków po ich wysłaniu. Warto również pamiętać, że można używać header() do ustawiania wielu różnych nagłówków, co otwiera szerokie możliwości w kontekście kontroli odpowiedzi HTTP. Użycie header() w połączeniu z odpowiednimi kodami statusu, jak 301 (trwałe przekierowanie) czy 302 (tymczasowe przekierowanie), pozwala na lepsze zarządzanie SEO oraz doświadczeniem użytkowników.
Pytanie 2
Wskaż, które z poniższych zdań jest prawdziwe w odniesieniu do definicji stylu: ``````
A. Odnośnik będzie napisany czcionką o rozmiarze 14 punktów
B. Akapit będzie przekształcany na małe litery
C. Zdefiniowano dwie klasy
D. Jest to styl zasięg lokalny
W tym kodzie CSS masz zdefiniowane dwie klasy: 'niebieski' i 'czerwony', które są przypisane do elementów TD. To super, bo te klasy zmieniają kolor tekstu w tabeli, a to jest zgodne z tym, jak działają kaskadowe arkusze stylów (CSS). Klasa 'niebieski' ustawia tekst na niebiesko, a 'czerwony' na czerwono. Dzięki takim klasom można zaoszczędzić sporo czasu, bo używasz tych samych stylów w różnych miejscach w HTML. Widać, że pomyślałeś o organizacji swojego kodu. Dodatkowo, masz też style dla elementów P i A — P jest niebieski i ma czcionkę 14 punktów w kursywie, a A ma większą 16-punktową czcionkę. To pokazuje, jak elastyczne jest CSS w stylizacji różnych elementów. Fajnie, że trzymasz się dobrych praktyk w programowaniu, bo to naprawdę ułatwia późniejsze modyfikacje.
Pytanie 3
Jaką wartość zwróci funkcja zao, która została zdefiniowana w języku C++, gdy zostanie wywołana z argumentem 3.55?
intzao(floatx) {returnx+0.5;}
A. 4
B. 3.5
C. 3
D. 4.05
Funkcja zaofloat zdefiniowana w C++ przyjmuje argument typu float, a następnie zwraca go po dodaniu do niego wartości 0.5. W przypadku wywołania tej funkcji z argumentem 3.55, najpierw dodajemy 0.5, co daje nam 4.05. Następnie, w kontekście C++, funkcja ta nie została jeszcze zaimplementowana w sposób, który by zaokrąglał wynik. W rezultacie, gdybyśmy zaokrąglili wynik do najbliższej liczby całkowitej, otrzymalibyśmy 4. Takie podejście jest zgodne z zasadami zaokrąglania, które mówią, że liczby z częścią dziesiętną równą lub większą od 0.5 powinny być zaokrąglane w górę. Tego rodzaju funkcje są powszechnie stosowane w programowaniu, zwłaszcza w kontekście obliczeń finansowych i inżynieryjnych, gdzie precyzyjne zarządzanie wartościami liczbowymi jest kluczowe. Warto dodać, że w C++ istnieją standardowe funkcje, takie jak round() z biblioteki cmath, które mogą być wykorzystywane do efektywnego zaokrąglania wartości do najbliższej liczby całkowitej, co może być przydatne w wielu sytuacjach.
Pytanie 4
O zmiennej predefiniowanej
$_POST
w języku PHP można stwierdzić, że
A. jest rozwiniętą wersją tablicy $_SESSION
B. zawiera dane bezpośrednio dostarczone do skryptu z ciasteczka
C. zawiera dane przesłane do skryptu za pośrednictwem formularza
D. jest odwzorowaniem tablicy $_COOKIE
Odpowiedź, że zmienna predefiniowana $_POST zawiera dane przesłane do skryptu z formularza, jest w pełni poprawna. W języku PHP, $_POST to jedna z superglobalnych tablic, która umożliwia dostęp do danych przesyłanych metodą POST. Metoda ta jest powszechnie stosowana w formularzach HTML, gdzie użytkownik może wprowadzać dane, które następnie są wysyłane do serwera. Na przykład, formularz kontaktowy, w którym użytkownik wprowadza swoje imię i adres e-mail, może być przetwarzany za pomocą $_POST, co pozwala na łatwą i bezpieczną obsługę danych. Dobrą praktyką jest również walidacja danych przed ich użyciem, aby zminimalizować ryzyko ataków, takich jak SQL Injection czy XSS. Dzięki zastosowaniu $_POST, programiści mogą przechwytywać i przetwarzać dane użytkowników w bardziej zaawansowany sposób, co pozwala na dynamiczne generowanie treści i interakcję z użytkownikami.
Pytanie 5
Kaskadowe arkusze stylów są tworzone w celu
A. określenia metod formatowania elementów na stronie internetowej
B. ulepszenia nawigacji dla użytkownika
C. dodania na stronie internetowej treści tekstowych
D. zwiększenia szybkości ładowania grafiki na stronie internetowej
Kaskadowe arkusze stylów (CSS) są kluczowym elementem w projektowaniu stron internetowych, ponieważ umożliwiają one definiowanie sposobu formatowania i prezentacji elementów na stronie. CSS pozwala na oddzielenie treści od formy, co oznacza, że programiści mogą skupić się na tworzeniu struktury dokumentu HTML, podczas gdy stylistyka i układ są kontrolowane przez arkusze stylów. Przykładem zastosowania CSS jest stylizacja nagłówków, paragrafów czy list, gdzie można dostosować czcionki, kolory, marginesy oraz inne właściwości wizualne. Dzięki użyciu selektorów i reguł CSS, twórcy stron mają pełną kontrolę nad tym, jak każdy element będzie wyglądał, co pozwala na tworzenie responsywnych i estetycznych interfejsów. Ponadto, CSS obsługuje kaskadowość, co oznacza, że reguły mogą być dziedziczone i nadpisywane, co zwiększa elastyczność i wydajność procesu stylizacji. Warto również zwrócić uwagę na standardy W3C, które definiują najlepsze praktyki i zalecenia dotyczące użycia CSS, co przyczynia się do poprawy dostępności i zgodności stron internetowych.
Pytanie 6
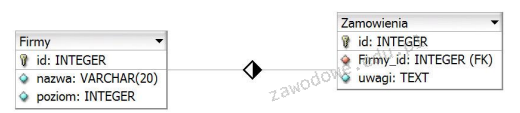
Tabele: Firmy oraz Zamówienia są ze sobą powiązane relacją jeden do wielu. Aby uzyskać tylko identyfikatory zamówień wraz z odpowiadającymi im nazwami firm dla przedsiębiorstw, których poziom wynosi 4, należy użyć polecenia
A. SELECT Zamówienia.id, nazwa FROM Zamówienia JOIN Firmy ON Zamówienia.Firmy_id = Firmy.id WHERE poziom = 4
B. SELECT Zamówienia.id, nazwa FROM Zamówienia JOIN Firmy ON Zamówienia.id = Firmy.id WHERE poziom = 4
C. SELECT Zamówienia.id, nazwa FROM Zamówienia JOIN Firmy WHERE poziom = 4
D. SELECT id, nazwa FROM Zamówienia JOIN Firmy ON Zamówienia.Firmy_id = Firmy.id WHERE poziom = 4
Odpowiedź numer 2 jest prawidłowa, ponieważ wykorzystuje poprawne połączenie między tabelami Zamowienia i Firmy przy użyciu klucza obcego Firmy_id, co jest zgodne z praktykami projektowania relacyjnych baz danych. Klucz obcy w tabeli Zamowienia wskazuje na klucz główny w tabeli Firmy, co odzwierciedla relację jeden do wielu, gdzie jedna firma może mieć wiele zamówień. Właściwe stosowanie kluczy obcych nie tylko poprawia integralność danych, ale także ułatwia zrozumienie struktury danych. Właściwe użycie klauzuli JOIN z warunkiem ON pozwala na efektywne powiązanie rekordów z obu tabel. Warunek WHERE poziom = 4 pozwala na filtrowanie wyników, co jest kluczowe w analizie danych, umożliwiając wyodrębnienie tylko tych rekordów, które spełniają określone kryteria. Dzięki temu możemy uzyskać zestaw danych zawierający tylko te zamówienia, które pochodzą od firm o określonym poziomie, co jest częstym wymogiem w raportach biznesowych. Praktyczne użycie tego typu zapytań jest niezastąpione w aplikacjach analitycznych i systemach raportowania, gdzie precyzyjne filtrowanie i łączenie danych ma kluczowe znaczenie dla podejmowania decyzji biznesowych. Dbając o zgodność z najlepszymi praktykami, takie zapytania powinny być dobrze testowane i optymalizowane, aby zapewnić ich efektywność w dużych zbiorach danych.
Pytanie 7
W języku PHP symbol "//" oznacza
A. operator alternatywy.
B. początek programu.
C. operator dzielenia całkowitego.
D. początek komentarza jednoliniowego
Znak "//" w PHP to początek komentarza jednoliniowego. Komentarze to naprawdę ważna część kodowania, bo dzięki nim można dodawać notatki, które wyjaśniają, co się dzieje w kodzie. Ułatwia to późniejsze zrozumienie przy pracy nad projektem. Kiedy programista wpisuje "//", mówi interpreterowi PHP, żeby zignorował wszystko, co znajduje się w tej linii po tym znaku. Dzięki temu można opisywać funkcje czy klasy albo tymczasowo wyłączać część kodu, gdy testujemy różne rzeczy. To dobra praktyka, bo czytelność i dokumentacja kodu są kluczowe, szczególnie w większych projektach. Przykładowo, można zobaczyć taki komentarz: // Funkcja oblicza sumę dwóch liczb function suma($a, $b) { return $a + $b; } Dzięki takiemu komentarzowi inny programista szybko zrozumie, co ta funkcja robi, co jest super ważne w sytuacjach, gdy w zespole jest więcej osób.
Pytanie 8
Znak pisarski @ jest czytany w języku angielskim jako
A. on.
B. ape.
C. at.
D. monkey.
Poprawna odpowiedź to „at”, bo właśnie tak w języku angielskim czyta się znak @. Ten znak nazywa się w terminologii technicznej „at sign” albo „commercial at”. W praktyce najczęściej spotykasz go w adresach e‑mail, np. w zapisie [email protected] czytamy to jako „user at example dot com”. W dokumentacji technicznej, w standardach internetowych (RFC dotyczących e‑maili, jak RFC 5322) i w różnych tutorialach programistycznych zawsze przyjmuje się właśnie taką wymowę i nazwę. W kontekście tworzenia stron WWW i programowania webowego dobrze jest kojarzyć zarówno nazwę znaku, jak i jego typowe zastosowanie. W HTML sam znak @ nie ma specjalnego znaczenia składniowego, ale pojawia się w treści, np. w linkach mailto: <a href="mailto:[email protected]">. W CSS czasem widzisz tzw. at‑rules, np. @media, @import, @font-face – tu też w dokumentacji wprost jest mowa o „at‑rule”. W różnych językach programowania webowego symbol @ ma różne role: w PHP oznacza operator wyciszający błędy (co zresztą jest uznawane za złą praktykę), w wielu frameworkach jest używany w szablonach (np. Blade w Laravelu: @if, @foreach), w adnotacjach czy dekoratorach w innych technologiach. Moim zdaniem warto po prostu przyzwyczaić się do angielskiej nazwy „at”, bo w pracy z dokumentacją, Stack Overflow, oficjalnymi specyfikacjami czy logami systemowymi praktycznie nikt nie używa żadnych lokalnych, zabawnych nazw. To drobny szczegół, ale w branży IT takie detale językowe bardzo ułatwiają komunikację w zespole i z klientem.
Pytanie 9
Który z podanych kodów XHTML sformatuje tekst zgodnie z określonym schematem?
A. Odpowiedź C
B. Odpowiedź B
C. Odpowiedź A
D. Odpowiedź D
W przypadku innych odpowiedzi, problemem jest niewłaściwe użycie znacznika formatowania tekstu lub błędna struktura kodu. Odpowiedź A używa znacznika b zarówno dla słowa kota, jak i kot, co powoduje, że oba słowa są pogrubione zamiast tylko jednego. Odpowiedź B zawiera niepoprawne użycie znaczników, gdzie b i i są używane zamiennie, co jest niezgodne z podanym wzorem, ponieważ słowo kota powinno być pogrubione, a kot kursywą. W odpowiedzi C znaczniki są użyte niewłaściwie, ponieważ br nie jest zamknięty w cudzysłowie, co może prowadzić do problemów z walidacją w standardzie XHTML oraz nie spełnia wymogu przełamania linii. W każdym przypadku kluczowym błędem jest brak zrozumienia semantycznego znaczenia znaczników oraz ich zależności od struktury dokumentu XHTML. Niepoprawne użycie znaczników prowadzi do nieprawidłowego wyrenderowania tekstu, co jest częstym błędem przy formatowaniu, wynikającym z nieprawidłowego zrozumienia różnicy między znacznikami b i i oraz ich zamierzonego użycia. Dlatego ważne jest, aby zawsze upewnić się, że struktura dokumentu i użycie znaczników jest zgodne z oczekiwaniami i standardami XHTML.
Pytanie 10
Zestawienie dwóch kolorów znajdujących się po przeciwnych stronach na kole barw stanowi zestawienie
A. sąsiednim
B. dopełniającym
C. monochromatycznym
D. trójkątnym
Połączenie dwóch barw leżących po przeciwnych stronach w kole barw określane jest mianem barw dopełniających. Barwy te, takie jak czerwony i zielony czy niebieski i pomarańczowy, wzajemnie się uzupełniają, co oznacza, że gdy są używane razem, podkreślają się nawzajem, tworząc intensywniejszy i bardziej dynamiczny efekt wizualny. W praktyce wykorzystuje się je w projektowaniu graficznym, malarstwie oraz fotografii, gdzie kontrastujące barwy przyciągają uwagę widza, co jest szczególnie ważne w reklamie czy przy tworzeniu wizualnych identyfikacji. Zastosowanie barw dopełniających jest również istotne w teorii kolorów, szczególnie w kontekście harmonii barwnej. Warto pamiętać, że użycie barw dopełniających może również wpływać na percepcję emocjonalną odbiorcy, co jest niezwykle istotne w kontekście marketingu czy sztuki.
Pytanie 11
Zdarzenie JavaScript onmousedown występuje, gdy
A. wskaźnik myszy komputerowej wyszedł poza obręb obiektu.
B. został naciśnięty dwa razy klawisz myszy komputerowej.
C. został wciśnięty dowolny klawisz myszy komputerowej na danym elemencie.
D. wskaźnik myszy komputerowej znalazł się w obrębie obiektu.
Poprawnie – zdarzenie onmousedown w JavaScript wywołuje się dokładnie w momencie, gdy użytkownik naciska dowolny klawisz myszy na danym elemencie. Nie ma znaczenia, czy to jest lewy, prawy czy środkowy przycisk, samo fizyczne wciśnięcie przycisku nad elementem powoduje uruchomienie tego eventu. Z punktu widzenia przeglądarki jest to bardzo wczesny etap interakcji myszą: najpierw pojawia się onmousedown, później ewentualnie onmouseup, a dopiero z kombinacji tych dwóch czasem wynika onclick. Moim zdaniem warto to sobie dobrze poukładać, bo w praktyce front-endowca to jedna z podstawowych rzeczy przy obsłudze interfejsu. onmousedown jest używany wszędzie tam, gdzie chcesz zareagować natychmiast po naciśnięciu przycisku, a nie dopiero po jego puszczeniu. Klasyczny przykład to przeciąganie elementów (drag and drop): w onmousedown zapamiętujesz, że użytkownik „złapał” element, podpinasz nasłuch na mousemove, a w mouseup kończysz przeciąganie. Innym typowym zastosowaniem są własne przyciski i kontrolki, gdzie chcesz np. zmienić styl od razu po wciśnięciu (wrażenie wciśniętego guzika), albo rozpocząć jakąś akcję ciągłą, np. przytrzymanie przycisku powoduje powiększanie mapy czy przewijanie listy. W nowoczesnym JavaScript raczej używa się addEventListener("mousedown", handler) zamiast atrybutu onmousedown w HTML, bo to zgodne z dobrymi praktykami separacji logiki od struktury (HTML + JS osobno). Sam event obiektu MouseEvent przekazuje też szczegóły, np. który przycisk został naciśnięty (właściwość button), pozycję kursora, stan klawiszy modyfikujących itd. Dobrze wiedzieć, że onmousedown nie jest powiązany z wyjściem kursora poza element ani z podwójnym kliknięciem – od tego są inne zdarzenia, co często myli początkujących.
Pytanie 12
Arkusze stylów w formacie kaskadowym są tworzone w celu
A. blokowania wszelkich zmian w wartościach znaczników już przypisanych w pliku CSS
B. połączenia struktury dokumentu strony z odpowiednią formą jej wizualizacji
C. nadpisywania wartości znaczników, które już zostały ustawione na stronie
D. ułatwienia formatowania strony
Wybór błędnych odpowiedzi może wynikać z nieporozumienia dotyczącego funkcji kaskadowych arkuszy stylów i ich zastosowania w procesie tworzenia stron internetowych. Odpowiedzi sugerujące blokowanie jakichkolwiek zmian w wartościach znaczników w pliku CSS są mylące, ponieważ CSS zaprojektowane jest właśnie po to, aby umożliwiać modyfikacje stylów. Arkusze stylów nie blokują zmian, tylko lepiej organizują i strukturalizują kod, co sprzyja łatwiejszemu wprowadzaniu przyszłych poprawek. Z kolei połączenie struktury dokumentu strony z właściwą formą prezentacji jest bardziej związane z HTML, który odpowiada za strukturę treści strony. CSS natomiast odpowiada głównie za stylizację i nie ma na celu bezpośredniego łączenia tych aspektów, lecz oddzielenie ich. Warto również zauważyć, że nadpisywanie wartości znaczników na stronie to szczególna funkcjonalność CSS, ale nie jest to jej główny cel. Główna idea CSS polega na uproszczeniu procesu formatowania, co podkreśla znaczenie kaskadowości, gdzie reguły mogą być dziedziczone i nadpisywane w sposób przemyślany i kontrolowany. Typowymi błędami myślowymi w tym kontekście są zamiana celów CSS z HTML oraz brak zrozumienia mechanizmów kaskadowości, co prowadzi do nieprawidłowych wniosków na temat roli, jaką CSS odgrywa w projektowaniu stron internetowych.
Pytanie 13
Którą funkcję z menu Kolory programu GIMP użyto, w celu uzyskania efektu przedstawionego w filmie?
A. Barwienie.
B. Progowanie.
C. Krzywe.
D. Inwersja.
Prawidłowo wskazana funkcja to „Progowanie”, bo dokładnie ona zamienia obraz kolorowy lub w odcieniach szarości na obraz dwuwartościowy: piksel jest albo czarny, albo biały, w zależności od tego, czy jego jasność przekracza ustawiony próg. W GIMP-ie znajdziesz ją w menu Kolory → Progowanie. Suwakami ustalasz zakres poziomów jasności, które mają zostać potraktowane jako „białe”, a wszystko poza tym zakresem staje się „czarne”. Efekt, który się wtedy uzyskuje, jest bardzo charakterystyczny: mocno kontrastowy, bez półtonów, coś w stylu skanu czarno-białego lub grafiki do druku na ploterze tnącym. Z mojego doświadczenia progowanie świetnie nadaje się do przygotowania logotypów, szkiców technicznych, schematów, a także do wyciągania konturów z lekko rozmytych zdjęć. Często używa się go też przed wektoryzacją, żeby program śledzący krawędzie miał wyraźne granice między czernią a bielą. W pracy z grafiką na potrzeby stron WWW próg bywa stosowany np. przy tworzeniu prostych ikon, piktogramów albo masek (maski przezroczystości można przygotować właśnie na bazie obrazu progowanego). Dobrą praktyką jest najpierw sprowadzenie obrazu do odcieni szarości i dopiero potem użycie progowania, bo wtedy masz większą kontrolę nad tym, jak rozkłada się jasność i gdzie wypadnie granica progu. Warto też pamiętać, że progowanie jest operacją destrukcyjną – traci się informacje o półtonach – więc najlepiej pracować na kopii warstwy, żeby w razie czego móc wrócić do oryginału i poprawić ustawienia progu.
Pytanie 14
Jak utworzyć klucz obcy na wielu kolumnach podczas definiowania tabeli?
A. CONSTRAINT fk_osoba_uczen FOREIGN KEY ON(nazwisko, imie) REFERENCES osoby (nazwisko, imie)
B. CONSTRAINT fk_osoba_uczen FOREIGN KEY(nazwisko, imie) REFERENCES osoby (nazwisko, imie)
C. CONSTRAINT (nazwisko, imie) FOREIGN REFERENCES KEY osoby (nazwisko, imie)
D. CONSTRAINT (nazwisko, imie) FOREIGN KEY REFERENCES osoby (nazwisko, imie)
Pierwsza z niepoprawnych odpowiedzi zawiera błąd w składni, ponieważ nieprawidłowo łączy elementy definicji klucza obcego oraz niepoprawnie używa słowa kluczowego 'REFERENCES' przed 'FOREIGN KEY', co narusza standard SQL. W drugiej niepoprawnej odpowiedzi również występuje błąd w kolejności słów kluczowych, co czyni konstrukcję naruszającą zasady składni SQL. W trzeciej odpowiedzi z kolei mamy do czynienia z błędnym użyciem 'ON', które nie jest częścią definicji klucza obcego w tym kontekście. Ponadto, konstrukcja 'FOREIGN REFERENCES KEY' nie ma sensu w kontekście SQL, ponieważ nie istnieje pojęcie 'REFERENCES' obok 'FOREIGN KEY'. W związku z tym, wszystkie trzy niepoprawne odpowiedzi nie spełniają wymogów poprawnej definicji klucza obcego, co prowadzi do problemów z integralnością danych i błędami podczas wykonywania zapytań w bazie danych. Rekomendowane jest zawsze przestrzeganie standardów SQL i testowanie zapytań w bezpiecznym środowisku przed ich zastosowaniem w produkcji.
Pytanie 15
W języku PHP funkcja trim ma za zadanie
A. z obu końców napisu usuwać białe znaki lub inne znaki podane w parametrze.
B. wyznaczyć długość napisu.
C. zmniejszać napis o wskazaną w parametrze liczbę znaków.
D. porównywać dwa napisy i wypisywać część wspólną.
Poprawnie – funkcja trim() w PHP służy do usuwania z obu końców napisu tzw. znaków niechcianych, domyślnie białych znaków, czyli spacji, tabulatorów, znaków nowej linii, powrotu karetki itp. Kluczowe jest tu słowo „z końców” – trim nie rusza środka łańcucha, modyfikuje tylko początek i koniec. Składnia jest prosta: trim(string $string, string $characters = " \n\r\t\0\x0B"). Drugi parametr jest opcjonalny i pozwala samodzielnie określić zestaw znaków, które mają być usunięte. Przykład z praktyki: bardzo często po odebraniu danych z formularza stosuje się $name = trim($_POST['name']); żeby usunąć przypadkowe spacje przed i po imieniu użytkownika. Dzięki temu porównywanie napisów, walidacja czy zapisywanie do bazy danych jest bardziej przewidywalne i zgodne z dobrymi praktykami. Moim zdaniem trim to jedna z takich małych funkcji, które powinny wejść w nawyk – szczególnie przy obsłudze inputów użytkownika, importu danych z plików CSV, parsowaniu logów czy przygotowywaniu danych do serializacji. Warto też znać powiązane funkcje: ltrim() usuwa znaki tylko z lewej strony, a rtrim() (alias chop()) tylko z prawej. Dobrą praktyką jest stosowanie trim bezpośrednio po pobraniu danych z zewnętrznych źródeł, zanim zaczniemy robić jakiekolwiek porównania, zapisy do bazy czy generowanie kluczy. Pozwala to uniknąć bardzo irytujących błędów typu „ten sam użytkownik, ale inne spacje”, które potem trudno debugować. W profesjonalnych aplikacjach webowych obróbka łańcuchów, w tym właśnie trim, jest standardowym elementem warstwy walidacji i normalizacji danych wejściowych.
Pytanie 16
W tabeli artykuly przeprowadzono poniższe operacje związane z uprawnieniami użytkownika jan.
GRANT ALL PRIVILEGES ON artykuły TO jan
REVOKE SELECT, UPDATE ON artykuly FROM jan
Jakie będą uprawnienia użytkownika jan po wykonaniu tych operacji?
A. tworzenia tabeli oraz aktualizowania danych w niej
B. aktualizowania informacji oraz przeglądania tabeli
C. przeglądania tabeli
D. tworzenia tabel oraz ich zapełniania danymi
Odpowiedź "tworzenia tabeli i wypełniania jej danymi" jest poprawna, ponieważ po wykonaniu polecenia GRANT ALL PRIVILEGES ON artykuły TO jan, użytkownik jan zyskuje pełnię praw do bazy danych, co obejmuje możliwość tworzenia nowych tabel oraz wypełniania ich danymi. Takie uprawnienia są niezbędne, jeśli jan ma zająć się rozwijaniem struktury bazy danych w kontekście projektów lub aplikacji. W praktyce, przydzielanie takich uprawnień powinno być starannie przemyślane w kontekście bezpieczeństwa. W dobrych praktykach zarządzania bazami danych stosuje się zasadę najmniejszych uprawnień, co oznacza, że użytkownicy powinni mieć tylko te prawa, które są im niezbędne do wykonywania ich zadań. Dzięki temu minimalizuje się ryzyko przypadkowego lub celowego usunięcia danych. W przypadku jana, jego pełne uprawnienia do artykułów pozwolą mu wprowadzać dane nie tylko do istniejących tabel, ale także tworzyć nowe struktury, co jest kluczowe w dynamicznych środowiskach, gdzie wymagane są częste zmiany.
Pytanie 17
Jak wybrać nazwy produktów z tabeli sprzet zawierającej pola: nazwa, cena, liczbaSztuk, dataDodania, które zostały dodane w roku 2021, a ich cena jest poniżej 100 zł lub liczba sztuk przekracza 4, w sekcji WHERE?
A. WHERE dataDodania LIKE '2021%' AND (cena < 100 OR liczbaSztuk > 4)
B. WHERE dataDodania LIKE '2021%' OR cena < 100 OR liczbaSztuk > 4
C. WHERE dataDodania LIKE '2021%' OR (cena < 100 AND liczbaSztuk > 4)
D. WHERE dataDodania LIKE '2021%' AND cena < 100 AND liczbaSztuk > 4
W analizowanych odpowiedziach błędy wynikają z niepoprawnego rozumienia operatorów logicznych oraz ich zastosowania w kontekście filtracji danych. Pierwsza z propozycji, która używa operatora OR w każdym warunku, powoduje, że zapytanie obejmie zbyt szeroki zakres danych. Oznacza to, że każdy produkt dodany w 2021 roku, niezależnie od ceny czy liczby sztuk, zostanie uwzględniony, co jest sprzeczne z zamierzonym celem. Operator OR w tym przypadku nie spełnia wymagań, ponieważ musimy mieć produkty, które są jednocześnie związane z danym rokiem oraz spełniają przynajmniej jeden z dwóch dodatkowych kryteriów. Odpowiedzi korzystające z operatora AND w każdym warunku również są błędne, ponieważ wykluczą z wyników produkty, które mogą mieć cenę wyższą niż 100 zł, ale liczba sztuk przekracza 4. Taki sposób myślenia prowadzi do zbyt restrykcyjnych filtrów, co może uniemożliwić pozyskanie wartościowych danych. Ważne jest, aby w zapytaniach SQL stosować operator AND do łączenia warunków, gdzie wszystkie muszą być spełnione, oraz operator OR w sytuacjach, gdy wystarczy spełnienie jednego z warunków. Poprawny dobór tych operatorów ma kluczowe znaczenie dla wydajności zapytań oraz dokładności wyników, zwłaszcza w kontekście dużych zbiorów danych, takich jak bazy danych produktów.
Pytanie 18
Przygotowując raport w systemie zarządzania relacyjnymi bazami danych, można uzyskać
A. dodawanie danych do tabel
B. analizę wybranych danych
C. aktualizowanie danych w tabelach
D. usuwanie danych z tabel
W kontekście systemów obsługi relacyjnych baz danych, raportowanie odgrywa kluczową rolę w analizie danych. Wykonywanie raportu umożliwia użytkownikom dostęp do wybranych informacji, co pozwala na podejmowanie świadomych decyzji opartych na danych. Analiza danych to proces przetwarzania informacji w celu wydobycia wartościowych wniosków. Przykłady zastosowania to generowanie raportów sprzedażowych, finansowych czy analizy trendów klientów. W raportach można wykorzystać różne techniki, takie jak filtrowanie, grupowanie czy agregowanie danych, co umożliwia prezentację wyników w przystępnej formie graficznej. Dodatkowo, standardy takie jak SQL (Structured Query Language) są powszechnie używane do wykonywania zapytań w relacyjnych bazach danych, co pozwala na efektywne przeszukiwanie i analizowanie danych. W praktyce, raporty mogą być generowane na podstawie zapytań do bazy danych i mogą obejmować różne parametry, co zwiększa ich użyteczność w podejmowaniu decyzji strategicznych i operacyjnych.
Pytanie 19
Aby ułatwić dodawanie oraz modyfikowanie danych w tabeli, konieczne jest zdefiniowanie
A. filtru.
B. zapytania SELECT.
C. formularza.
D. sprawozdania.
Kwerenda SELECT jest narzędziem służącym do pobierania danych z bazy danych. Chociaż może być wykorzystywana do wyświetlania informacji, nie jest ona odpowiednia do wprowadzania lub edytowania danych. Kwerenda SELECT jedynie odzwierciedla stan bazy danych w momencie jej wykonania, nie oferując możliwości edycji czy wprowadzania nowych informacji. Podobnie, raport jest narzędziem, które syntetyzuje dane i przedstawia je w zrozumiały sposób, jednak jego funkcjonalność ogranicza się do prezentacji wyników, a nie do interakcji z danymi. Raporty są przydatne do analizowania danych, ale nie umożliwiają użytkownikom zmiany ich zawartości. Z kolei filtr to mechanizm, który pozwala na ograniczenie wyświetlanych danych na podstawie określonych kryteriów. Filtry są użyteczne w kontekście przeszukiwania danych, ale ich rola nie obejmuje edytowania ani wprowadzania nowych informacji. Filtry pomagają w selekcji danych, ale nie zmieniają ich stanu, co czyni je niewłaściwym wyborem dla zadania edycji danych. W skrócie, wszystkie wymienione opcje mają swoje zastosowania, lecz nie są w stanie zastąpić funkcji formularza w kontekście jednostkowego wprowadzania i edytowania danych.
Pytanie 20
Taki styl CSS sprawi, że na stronie internetowej
ul{ list-style-image: url('rys.gif'); }
A. punkt listy nienumerowanej będzie rys.gif
B. rys.gif wyświetli się jako tło dla listy nienumerowanej
C. każdy punkt listy zyska osobne tło z grafiki rys.gif
D. rys.gif stanie się ramką dla listy nienumerowanej
Zrozumienie właściwości CSS jest kluczowe dla tworzenia poprawnych i estetycznych stron internetowych. List-style-image to właściwość, która zastępuje domyślny punktor listy nienumerowanej obrazkiem, co było poprawnie wskazane w pierwszej odpowiedzi. Błędne jest jednak myślenie, że obraz rys.gif stanie się ramką dla listy. Taka funkcjonalność wymaga użycia właściwości CSS border, a nie list-style-image. Ramki wokół elementów HTML definiowane są za pomocą właściwości takich jak border-style, border-width i border-color. Następne nieporozumienie dotyczy myśli, że każdy punkt listy będzie miał osobne tło z obrazkiem. Aby osiągnąć ten efekt, należałoby użyć właściwości background-image dla każdego elementu listy (li), a nie list-style-image na poziomie ul. Ostatnim błędnym wnioskiem jest przypuszczenie, że rys.gif stanie się tłem całej listy nienumerowanej. Właściwość, która to umożliwia, to background-image, a nie list-style-image. Wybierając właściwą metodę, można precyzyjnie dostosować styl listy do zamierzonych efektów graficznych. Poprawne zrozumienie i zastosowanie tych właściwości jest kluczowe dla poprawnego tworzenia arkuszy stylów CSS i uniknięcia nieporozumień w projektowaniu wizualnym stron.
Pytanie 21
Po wykonaniu poniższego kodu JavaScript, co będzie przechowywać zmienna str2?
var str1 = "JavaScript"; var str2 = str1.substring(2,6);
A. vaScri
B. nvaScr
C. vaSc
D. avaS
Wykorzystując metodę substring w JavaScript możemy wyodrębnić fragmenty łańcucha znaków bazując na indeksach początkowym i końcowym. Indeksowanie w JavaScript zaczyna się od zera co oznacza że pierwszy znak ma indeks 0 drugi 1 i tak dalej. W przypadku zmiennej str1 przechowującej łańcuch JavaScript wywołanie str1.substring(2 6) zwraca fragment zaczynający się od znaku o indeksie 2 do znaku o indeksie 5 włącznie. Oznacza to że metoda wybiera znaki od trzeciego do szóstego nie wliczając znaku o indeksie 6. W praktyce oznacza to że z napisu JavaScript wybierane są znaki aScr co tworzy łańcuch vaSc. Zrozumienie działania metody substring jest kluczowe przy pracy z łańcuchami znaków w JavaScript. Jest to standardowa metoda używana powszechnie do manipulacji tekstem co ma zastosowanie w wielu dziedzinach programowania frontendowego i backendowego. Ważne jest aby pamiętać o zeroindeksowaniu co pozwala uniknąć typowych błędów związanych z nieprawidłowym określeniem zakresu znaków.
Pytanie 22
Częstotliwość próbkowania ma wpływ na
A. intensywność fali dźwiękowej utworu
B. standard jakości cyfrowego dźwięku
C. standard jakości analogowego dźwięku
D. poziom głośności nagranego utworu
Zrozumienie wpływu częstotliwości próbkowania na dźwięk cyfrowy jest kluczowe, a niektórzy mogą mylnie zakładać, że ma ona bezpośredni wpływ na inne aspekty dźwięku. Przykładowo, wiele osób może myśleć, że częstotliwość próbkowania wpływa na skalę głośności zapisanego utworu, co jest nieprawidłowe, ponieważ głośność jest określana przez amplitudę sygnału audio, a nie przez jego próbkowanie. Ponadto, jakość analogowego dźwięku nie podlega wpływowi częstotliwości próbkowania, ponieważ analogowe sygnały są ciągłe i nie wymagają próbkowania, aby być reprodukowane. Co więcej, amplituda fali dźwiękowej odnosi się do poziomu energii fali, a nie do jej częstotliwości próbkowania. Zrozumienie tej różnicy jest kluczowe dla prawidłowego pojmowania technologii dźwiękowej. Częstotliwość próbkowania ma znaczenie tylko w kontekście cyfrowego przetwarzania dźwięku, gdzie wpływa na jakość reprodukcji, ale nie ma zastosowania w analogowej sferze dźwięku. Typowe błędy myślowe w tej kwestii mogą wynikać z nieporozumienia dotyczącego różnicy między dźwiękiem analogowym a cyfrowym oraz sposobów, w jakie są one przetwarzane.
Pytanie 23
Klucz obcy w bazie danych jest tworzony w celu
A. stworzenia formularza do wprowadzania danych do tabeli
B. umożliwienia jednoznacznej identyfikacji rekordu w bazie danych
C. łączenia go z innymi kluczami obcymi w tabeli
D. określenia relacji 1..n łączącej go z kluczem głównym innej tabeli
Klucz obcy w tabeli jest fundamentalnym elementem w relacyjnych bazach danych, który umożliwia tworzenie relacji pomiędzy tabelami. W szczególności, definiuje relację 1..n, co oznacza, że jeden rekord w tabeli, w której znajduje się klucz główny, może być powiązany z wieloma rekordami w tabeli, która posiada klucz obcy. Taki mechanizm pozwala na strukturalne powiązanie danych, co jest kluczowe dla zapewnienia integralności referencyjnej. Na przykład, w bazie danych zarządzającej informacjami o klientach i ich zamówieniach, klucz obcy w tabeli zamówień może wskazywać na klucz główny w tabeli klientów, co pozwala na łatwe śledzenie, które zamówienia są przypisane do konkretnego klienta. Zastosowanie kluczy obcych wspiera również dobre praktyki projektowania baz danych, takie jak normalizacja, co minimalizuje redundancję danych i poprawia ich spójność. Zgodność z tymi zasadami jest zgodna z wytycznymi organizacji takich jak ISO/IEC 9075 oraz ANSI SQL, które promują efektywne zarządzanie danymi.
Pytanie 24
W SQL klauzula DISTINCT w poleceniu SELECT zapewnia, że zwrócone wyniki
A. będą uporządkowane.
B. nie zawiera będą duplikatów.
C. będą zgrupowane według wskazanego pola.
D. będą spełniały dany warunek.
Klauzula DISTINCT w języku SQL jest używana w instrukcji SELECT do eliminacji duplikatów w zwracanych wynikach zapytania. Gdy zapytanie wykorzystuje DISTINCT, zwracane są tylko unikalne rekordy, co oznacza, że identyczne wiersze występujące w zestawie wyników są redukowane do jednego wystąpienia. Działa to poprzez porównywanie wszystkich kolumn wymienionych w SELECT, co oznacza, że różnice w jakiejkolwiek kolumnie będą skutkować zwróceniem oddzielnych wierszy. Przykładowe zapytanie: SELECT DISTINCT nazwisko FROM pracownicy; zwróci listę unikalnych nazwisk pracowników, eliminując wszelkie powtórzenia. Klauzula DISTINCT jest szczególnie przydatna w raportach i analizach danych, gdyż pozwala na zrozumienie częstotliwości występowania różnych wartości. Zgodnie z SQL ANSI, użycie DISTINCT jest standardem, co oznacza, że jest obsługiwane przez wszystkie główne systemy zarządzania bazami danych, takie jak MySQL, PostgreSQL czy Oracle. Warto jednak pamiętać, że dodanie DISTINCT do zapytania może wpływać na wydajność, zwłaszcza w przypadku dużych zbiorów danych, ponieważ wymaga dodatkowych operacji przetwarzania, aby zidentyfikować i usunąć duplikaty.
Pytanie 25
Którego elementu nie powinno się umieszczać w nagłówku pliku HTML?
A. <link>
B. <meta>
C. <title>
D. <h2>
Odpowiedź <h2> jest poprawna, ponieważ ten znacznik rzeczywiście może być używany w nagłówku dokumentu HTML. Znaczniki nagłówków, takie jak <h1>, <h2>, <h3>, itd., są kluczowe dla strukturyzowania treści w HTML, ponieważ definiują hierarchię informacji na stronie. Zgodnie z najlepszymi praktykami SEO, właściwe użycie znaczników nagłówków nie tylko poprawia czytelność dla użytkowników, ale także umożliwia wyszukiwarkom lepsze zrozumienie struktury treści. Warto jednak zauważyć, że w nagłówku dokumentu HTML, który znajduje się w sekcji <head>, należy umieszczać jedynie metadane takie jak <title> oraz <meta>. Znaczniki nagłówków są przeznaczone do użycia w sekcji <body>, co podkreśla ich rolę w organizacji zawartości wizualnej. W praktyce, poprawne użycie znaczników nagłówków przyczynia się do lepszej nawigacji i dostępności treści dla użytkowników z różnymi potrzebami, w tym dla osób korzystających z technologii asystujących. Zastosowanie odpowiednich znaczników nagłówków może także wpłynąć na czas ładowania strony oraz jej ogólną wydajność.
Pytanie 26
W formularzu HTML użyto znacznika <input>. Pole to będzie służyło do wprowadzania maksymalnie
<inputtype="password"size="30"maxlength="20">
A. 20 znaków, które są widoczne w trakcie wprowadzania
B. 30 znaków, które nie są widoczne w polu tekstowym
C. 30 znaków, które są widoczne w trakcie wprowadzania
D. 20 znaków, które nie są widoczne w polu tekstowym
Odpowiedzi sugerujące, że w polu tekstowym mogą być widoczne znaki, są nieprawidłowe z kilku istotnych powodów. Przede wszystkim znaczenie atrybutu 'type' w znaczniku <input> jest kluczowe. Użycie 'type="password"' jednoznacznie wskazuje, że wprowadzone znaki będą maskowane, co ma na celu ochronę prywatności użytkownika. Odpowiedzi wskazujące na 30 znaków, które są widoczne, są całkowicie błędne, ponieważ atrybut 'size' definiuje szerokość pola, a nie maksymalną liczbę znaków, które można wprowadzić. To może prowadzić do mylnego wrażenia, że użytkownik ma pełen wgląd w wprowadzane dane, co nie jest zgodne z zamierzeniem tego typu pól. Oprócz tego, maksymalna liczba znaków 'maxlength' nie ma żadnego wpływu na to, czy znaki są widoczne, czy nie. Typowe błędy myślowe związane z tym zagadnieniem mogą obejmować niepoprawne zrozumienie roli atrybutów 'size' i 'maxlength'. Kluczowe jest, aby użytkownicy rozumieli, że odpowiednie projektowanie formularzy powinno zawsze uwzględniać bezpieczeństwo danych oraz ich ochronę, zwłaszcza w przypadku haseł. Dobre praktyki w zakresie UX/UI zalecają korzystanie z pól typu 'password' w sytuacjach wymagających ochrony danych, co przyczynia się do zwiększenia bezpieczeństwa aplikacji webowych.
Pytanie 27
Przyjmując, że użytkownik Adam nie miał dotychczas żadnych uprawnień, polecenie SQL przyzna mu prawa jedynie do
GRANTCREATE, ALTERONsklep.*TOadam;
A. tworzenia oraz modyfikowania struktury w tabeli sklep
B. dodawania i modyfikacji danych w tabeli sklep
C. dodawania i modyfikacji danych we wszystkich tabelach bazy sklep
D. tworzenia i zmiany struktury wszystkich tabel w bazie sklep
To, co zaznaczyłeś, jest jak najbardziej na miejscu. W tym SQL-u, 'GRANT CREATE, ALTER ON sklep.* TO adam;' dajesz użytkownikowi, czyli adamowi, możliwości tworzenia i zmieniania struktury wszystkich tabel w bazie 'sklep'. Słowo 'CREATE' pozwala mu na tworzenie nowych tabel, a 'ALTER' umożliwia mu wprowadzanie zmian w tych istniejących, na przykład dodawanie czy usuwanie kolumn. Ważne, żeby ogarnąć, że 'sklep.*' oznacza wszystkie tabele w danej bazie, co jest zgodne z dobrymi praktykami w zarządzaniu bazami danych. No bo jakby adam miał ochotę dodać nową tabelę albo zmodyfikować istniejącą, to musi mieć odpowiednie uprawnienia. Przykładem może być sytuacja, gdy administrator daje programiście dostęp do zmian w strukturze tabel, żeby móc dodać nowe funkcje do aplikacji – to naprawdę ważne dla rozwoju systemu.
Pytanie 28
Ile razy zostanie wykonana pętla napisana w języku PHP, przy założeniu, że zmienna kontrolna nie jest zmieniana w trakcie działania pętli? for ($i = 0; $i <= 10; $i+=2) { .... }
A. 5
B. 6
C. 10
D. 0
Wybór błędnych odpowiedzi wynika z nieprawidłowego zrozumienia działania pętli for oraz sposobu, w jaki zostają liczone iteracje. Odpowiedzi takie jak 0, 5 czy 10 są oparte na mylących założeniach. Na przykład, odpowiedzi 0 i 10 mogą sugerować, że pętla nie wykonuje żadnych iteracji lub, że wykonuje ich zbyt wiele, co jest sprzeczne z rzeczywistością. Pętla for, jak w tym przypadku, zaczyna od 0 i kończy na 10, a krok wynosi 2. Zmiana wartości $i przy każdym przejściu pętli jest kluczowym elementem do zrozumienia. Jeśli więc zmienna nie jest zmieniana, nie osiągnie ona wartości końcowej prawidłowo. Typowym błędem jest także myślenie o warunkach w sposób nieprecyzyjny; w tym wypadku warunek $i <= 10 jest spełniony dla wartości 10, co może mylić. W praktyce, programiści powinni zawsze dokładnie analizować zakres iteracji, aby uniknąć błędnych założeń. To zrozumienie jest fundamentalne, aby pisać wydajny i bezpieczny kod, stosując się do najlepszych praktyk programistycznych.
Pytanie 29
W bibliotece mysqli w PHP, aby uzyskać najbardziej aktualny komunikat o błędzie, można użyć funkcji
A. mysqli_error_list()
B. mysqli_use_result()
C. mysqli_error()
D. mysqli_errno()
Funkcja mysqli_error() w bibliotece mysqli języka PHP jest sposobem na uzyskanie ostatniego komunikatu o błędzie związanym z połączeniem lub zapytaniem SQL. Zwraca ona łańcuch znaków, który opisuje ostatni błąd związany z danym połączeniem. Jest to niezwykle przydatne narzędzie w procesie debugowania, ponieważ pozwala programiście szybko zidentyfikować źródło problemu. Na przykład, jeśli napotkasz błąd podczas wykonywania zapytania, możesz użyć mysqli_error($connection) po funkcji wykonującej zapytanie, aby uzyskać szczegółowy opis błędu. W kontekście dobrych praktyk programistycznych, zawsze należy obsługiwać błędy i nie ignorować ich, aby uniknąć trudności w przyszłości. Warto również pamiętać, że funkcja ta działa tylko w kontekście aktualnego połączenia bazodanowego, co oznacza, że przed jej użyciem musisz mieć aktywne połączenie. Przykład użycia: $result = mysqli_query($connection, $query); if (!$result) { echo mysqli_error($connection); }
Pytanie 30
W przypadku uszkodzenia serwera bazy danych, aby jak najszybciej przywrócić pełną funkcjonalność bazy danych, należy skorzystać z
A. kompletnej listy użytkowników serwera.
B. najnowszej wersji instalacyjnej serwera.
C. aktualnej wersji kopii zapasowej.
D. opisów struktur danych w tabelach.
Wybór aktualnej wersji kopii zapasowej jako najefektywniejszej metody przywrócenia działania bazy danych po awarii serwera jest zgodny z najlepszymi praktykami w zarządzaniu danymi. Kopie zapasowe stanowią kluczowy element strategii ochrony danych i powinny być regularnie tworzone, aby minimalizować ryzyko utraty informacji. W przypadku uszkodzenia serwera bazy danych, przywrócenie z najnowszej kopii zapasowej, która zawiera wszystkie aktualne dane, jest najskuteczniejszym sposobem odzyskania sprawności systemu. Kopie zapasowe można tworzyć na różne sposoby, w tym pełne, przyrostowe i różnicowe, co pozwala na elastyczność w zarządzaniu danymi. Zgodnie z rekomendacjami takich standardów jak ISO 27001, organizacje powinny wdrażać procedury tworzenia i zarządzania kopiami zapasowymi. Przykładowo, w przypadku awarii, administratorzy mogą szybko przywrócić bazę danych do stanu sprzed awarii, co znacząco ogranicza przestoje i straty finansowe związane z utratą danych.
Pytanie 31
W języku PHP wykonano poniższą operację. Aby uzyskać wszystkie rezultaty tego zapytania, należy:
$tab=mysqli_query($db,"SELECT imie FROM Osoby WHERE wiek < 18");
A. wyświetlić zmienną $db
B. użyć polecenia mysql_fetch
C. zaindeksować zmienną tab, tab[0] to pierwsze imię
D. zastosować pętlę z poleceniem mysqli_fetch_row
Pojawiające się koncepcje w odpowiedziach błędnych wskazują na niezrozumienie procesu pobierania danych z bazy danych w PHP. Zaindeksowanie zmiennej tab, w myśli o tym, że tab[0] zwróci pierwsze imię, jest podejściem, które nie uwzględnia, że zmienna $tab nie jest tablicą, lecz wynikiem zapytania, które może zawierać wiele wierszy. Otrzymujemy obiekt typu mysqli_result, który musi być przetworzony przez odpowiednie funkcje, a nie za pomocą prostego indeksowania. Zastosowanie polecenia mysql_fetch jest również niepoprawne, ponieważ mysql_fetch jest przestarzałą funkcją z rodziny mysql, która nie jest już wspierana i powinna być zastąpiona przez mysqli_fetch_ lub PDO. Wyświetlanie zmiennej $db nie ma sensu w kontekście uzyskania wyników zapytania, ponieważ zmienna ta odnosi się do połączenia z bazą danych, a nie do danych z zapytania. Te błędne podejścia prowadzą do szerszego problemu, którym jest brak znajomości mechanizmów obsługi baz danych w PHP oraz różnicy między różnymi typami metod dostępu do danych. Kluczowe jest, aby nie tylko znać składnię, ale także rozumieć koncepty stojące za pobieraniem i przetwarzaniem danych w systemach baz danych. Właściwe podejście do zarządzania danymi wymaga umiejętności korzystania z odpowiednich funkcji oraz znajomości struktur danych, które są wykorzystywane w PHP.
Pytanie 32
W kodzie źródłowym zapisanym w języku HTML wskaż błąd walidacji dotyczący tego fragmentu: ```
CSS
Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący ...```
A. Nieznany znacznik h6.
B. Znacznik br nie został poprawnie zamknięty.
C. Znacznik br nie może występować wewnątrz znacznika p.
D. Znacznik zamykający /b niezgodny z zasadą zagnieżdżania.
Twoja odpowiedź jest poprawna. Znacznik zamykający /b w badanym kodzie HTML jest niezgodny z zasadą zagnieżdżania. Zasada ta mówi, że znaczniki powinny być zamykane w odwrotnej kolejności do otwierania - zgodnie z modelem LIFO (Last In, First Out). W praktyce oznacza to, że jeśli otworzyliśmy na przykład najpierw znacznik <i>, a następnie <b>, to najpierw powinniśmy zamknąć <b>, a dopiero potem <i>. Nieprzestrzeganie tej zasady może prowadzić do nieoczekiwanych wyników podczas renderowania strony. Jest to istotne dla utrzymania czytelności i prawidłowego funkcjonowania kodu. W codziennej praktyce, szczególnie w większych projektach, stosowanie się do takich zasad pomaga utrzymać kod zrozumiałym i łatwym do zarządzania.
Pytanie 33
W JavaScript zdefiniowano obiekt. W jaki sposób można uzyskać dostęp do właściwości nazwisko?
var osoba = {imie: "Anna", nazwisko: "Kowalska", rok_urodzenia: 1985};
A. osoba::nazwisko
B. osoba[2]
C. osoba[1]
D. osoba.nazwisko
W przypadku niepoprawnych odpowiedzi osoba[2], osoba::nazwisko i osoba[1] odniesienie do właściwości obiektu w JavaScript zostało błędnie przedstawione. Metoda osoba[2] oraz osoba[1] sugeruje użycie notacji tablicowej, która jest stosowana do odwoływania się do elementów tablicy przez ich indeks. Jednak obiekt w JavaScript nie jest tablicą, a zestawem par klucz-wartość, dlatego stosowanie indeksów w tym kontekście nie ma zastosowania. Indeksowanie za pomocą nawiasów kwadratowych jest właściwe w przypadku tablic, natomiast obiekty wymagają dostępu przez klucze opisane jako stringi. Próba użycia osoba::nazwisko jest niepoprawna, ponieważ podwójny dwukropek nie jest częścią syntaksu JavaScript pozwalającego na dostęp do właściwości obiektu. Tego typu notacja może pojawiać się w innych językach programowania jak C++ jako operator zakresu, jednak w JavaScript jest pozbawiona sensu. Błędny wybór w tym przypadku wynika z niezrozumienia różnicy między różnymi strukturami danych oraz ich specyficznej składni w obrębie różnych języków programowania. Bardzo istotne jest zapamiętanie, że w JavaScript do właściwości obiektu najczęściej odwołuje się za pomocą notacji kropkowej, co jest nie tylko standardem, ale również poprawia czytelność i zrozumiałość kodu. Świadomość różnicy między tablicami a obiektami oraz umiejętność wyboru odpowiedniej składni są kluczowe w pisaniu efektywnego i poprawnego kodu w JavaScript. Poprawne zrozumienie tych różnic i składni pozwala unikać błędów i pisania kodu, który może być trudny do debugowania i zrównoważenia w przyszłości.
Pytanie 34
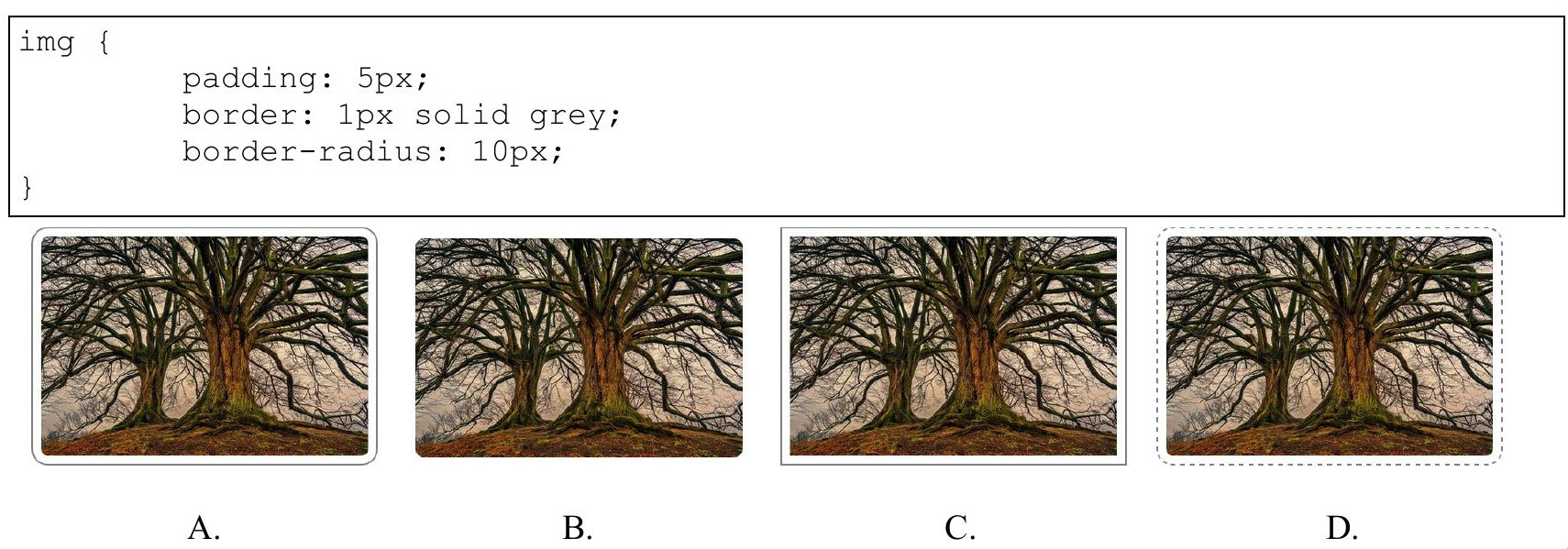
Który z przedstawionych obrazów został przetworzony przy użyciu podanego stylu CSS?
A. Rys. B
B. Rys. C
C. Rys. A
D. Rys. D
Wybór Rys. A jako poprawnej odpowiedzi jest uzasadniony zastosowaniem właściwości CSS, które są użyte w stylu. Styl CSS określa padding na 5 pikseli, co oznacza, że wokół obrazu powinna być przestrzeń wynosząca dokładnie 5 pikseli. Właściwość border ustawia obramowanie na 1 piksel, w kolorze szarym i o stylu solid, co oznacza ciągłą linię otaczającą obraz. Z kolei border-radius o wartości 10 pikseli zaokrągla rogi obramowania, co nadaje całości bardziej zaokrąglony kształt. Wszystkie te cechy są widoczne na obrazie Rys. A. W praktyce stosowanie właściwości takich jak border-radius jest często używane w projektach webowych, aby uzyskać bardziej estetyczne i nowoczesne efekty wizualne. Zaokrąglone krawędzie są estetycznie przyjemniejsze dla użytkownika i mogą poprawić czytelność oraz odbiór wizualny strony. Znajomość tych właściwości CSS jest niezbędna dla każdego front-end developera, który dąży do tworzenia nowoczesnych i funkcjonalnych interfejsów użytkownika. Praktyczne zastosowanie tego stylu może być widoczne w projektach stron internetowych, aplikacjach sieciowych oraz w tworzeniu elementów UI, które zachowują spójność wizualną z resztą projektu.
Pytanie 35
Jaki zapis znacznika <div> może występować w dokumencie HTML tylko raz, a jego ponowne użycie spowoduje pojawienie się błędów podczas walidacji dokumentu?
A. <div class="klasa1 klasa2">
B. <div class="klasa">
C. <div>
D. <div id="identyfikator">
Zapis <div class="klasa1 klasa2"> nie narusza zasad walidacji HTML, ponieważ atrybut class może występować wielokrotnie w obrębie dokumentu. Dzięki temu, można przypisać wiele klas do jednego elementu, co jest przydatne w przypadku stylizacji CSS, gdzie różne klasy mogą być wykorzystywane do różnych celów. Zastosowanie wielu klas umożliwia elastyczne zarządzanie stylami, jednak nie wpływa na unikalność elementów. Z kolei zapis <div class="klasa"> jest również poprawny i pozwala na przypisanie pojedynczej klasy do elementu. Klasy są przydatne w kontekście grupowania elementów lub stosowania do nich wspólnych stylów, co jest zgodne z zasadami modularności w CSS. Natomiast zapis <div> jest ogólnym rozwiązaniem, które nie wprowadza żadnych specyfikacji, ale również nie generuje błędów walidacyjnych. Zrozumienie różnicy między atrybutem id a atrybutem class jest kluczowe w HTML. Na przykład, stosując id, jesteśmy zobowiązani do jego unikalności, co nie jest wymagane dla klas. Dla wielu początkujących programistów mylenie tych dwóch atrybutów może prowadzić do nieporozumień i problemów z walidacją kodu. Przy projektowaniu stron internetowych należy skupić się na ich strukturyzacji oraz semantyce, aby zapewnić łatwiejsze zarządzanie kodem i jego przyszłą rozbudowę.
Pytanie 36
W JavaScript zapis a++; można przedstawić w inny sposób jako
A. a = a & 1
B. a = a + 1
C. a << 1
D. 1 += a
Odpowiedź 'a = a + 1;' jest poprawna, ponieważ dokładnie odzwierciedla działanie operatora inkrementacji 'a++;'. Operator '++' w JavaScript zwiększa wartość zmiennej o 1. W przypadku użycia 'a = a + 1;', operacja ta jest explicite zapisana jako przypisanie aktualnej wartości 'a' powiększonej o 1. Taki zapis jest często stosowany w sytuacjach, gdy chcemy lepiej zrozumieć, co się dzieje w kodzie, szczególnie dla początkujących programistów. Przykładowo, jeśli mamy zmienną, która przechowuje liczbę, możemy użyć 'a = a + 1;' w pętli, aby zliczać ilość iteracji. Warto zauważyć, że użycie operatora '++' jest bardziej zwięzłe i często preferowane w profesjonalnym kodzie, jednak zrozumienie, jak działa to na poziomie podstawowym, jest kluczowe. Dobrą praktyką jest dbałość o przejrzystość kodu, zwłaszcza w zespołach, gdzie różne osoby mogą pracować nad tym samym projektem.
Pytanie 37
W HTML formularzu użyto elementu <input>. Pole, które się pojawi, ma pozwalać na wprowadzenie maksymalnie
<inputtype="password"size="30"maxlength="20">
A. 20 znaków, które będą widoczne w trakcie wprowadzania
B. 30 znaków, które będą widoczne podczas wpisywania
C. 30 znaków, które nie będą widoczne w polu tekstowym
D. 20 znaków, które nie będą widoczne w polu tekstowym
Jeśli mówimy o znaczniku <input> w HTML, to dobrze jest wiedzieć, jak działają atrybuty typu maxlength i type. Atrybut maxlength pozwala ustawić maksymalną liczbę znaków w polu tekstowym. W polu typu password użytkownik może wpisać max 20 znaków, ale to, co widzisz, może być inne. Często myli się atrybut size z ograniczeniem liczby wprowadzanych znaków, ale tak naprawdę chodzi tylko o to, jak szerokie jest pole, więc nie zmienia jego funkcjonalności. Pole typu password ma na celu ukrycie wpisywanych znaków, co zazwyczaj oznacza, że to, co wpisujesz, zastąpione jest gwiazdkami lub kropkami, by nie było widać tego, co piszesz. Te rzeczy są ważne dla bezpieczeństwa aplikacji webowych. Ostatnio zauważyłem, że niektórzy mają problemy z rozumieniem tych atrybutów, co może prowadzić do błędów w obsłudze danych użytkowników i problemów z bezpieczeństwem.
Pytanie 38
Aby posortować listę uczniów według daty urodzenia w bazie danych, jakie polecenie należy zastosować?
A. SELECT imie,nazwisko,klasa from uczniowie order by nazwisko
B. SELECT imie,nazwisko,klasa from uczniowie order by rok_urodzenia
C. SELECT imie,nazwisko,klasa from uczniowie group by rok_urodzenia
D. SELECT imie,nazwisko,klasa from uczniowie where rok_urodzenia = 1994
Aby uporządkować listę uczniów według roku urodzenia w bazie danych, należy zastosować polecenie SQL 'SELECT imie,nazwisko,klasa from uczniowie order by rok_urodzenia'. Klauzula 'ORDER BY' jest kluczowa w SQL, ponieważ pozwala na sortowanie wyników zapytania według określonej kolumny, w tym przypadku 'rok_urodzenia'. Użycie tej klauzuli zapewnia, że wyniki są prezentowane w porządku rosnącym lub malejącym, co jest szczególnie przydatne, gdy chcemy analizować dane w kontekście czasowym. Na przykład, jeżeli mamy tabelę uczniów z kolumnami 'imie', 'nazwisko', 'klasa' oraz 'rok_urodzenia', użycie tego polecenia umożliwi nam nie tylko zobaczenie imion i nazwisk uczniów, ale również ich uporządkowanie według daty urodzenia. Zgodnie z normami SQL, jest to standardowa metoda sortowania danych, która zwiększa przejrzystość i użyteczność wyników. Przykładowo, jeśli w tabeli są uczniowie urodzeni w różnych latach, dzięki temu zapytaniu, najpierw zobaczymy uczniów urodzonych w najwcześniejszych latach, co może być istotne przy podejmowaniu decyzji organizacyjnych w szkole.
Pytanie 39
Która z poniższych grup znaczników HTML zawiera tagi używane do grupowania elementów oraz organizacji struktury dokumentu?
A. div, article, header
B. br, img, hr
C. span, strong, em
D. table, tr, td
Odpowiedź z <div>, <article> i <header> jest naprawdę trafna. Te znaczniki HTML są super ważne, bo pomagają w sensownym grupowaniu treści. <div> to taki uniwersalny kontener, który świetnie nadaje się do organizowania elementów, a zwłaszcza przy stylach CSS. Można nim łatwo zarządzać całymi sekcjami, co jest spoko. <article> z kolei to coś jak kawałek treści, który może działać samodzielnie, na przykład artykuł czy post na blogu. A <header>? On zdefiniuje nagłówki dla różnych sekcji, co ułatwia nawigację po stronie. To nie tylko pomaga użytkownikom, ale też robotom indeksującym. Fajnie też pamiętać, że korzystając z odpowiednich znaczników, nie tylko sprawiamy, że strona jest bardziej dostępna, ale też poprawiamy SEO, co jest kluczowe, żeby nasza witryna była widoczna w sieci.
Pytanie 40
Zgodnie z zasadami walidacji HTML5, prawidłowy zapis tagu hr to
A. </hr?>
B. </ hr />
C. <hr>
D. </ hr>
Znak <hr> jest poprawnym zapisem znacznika poziomej linii w HTML5. Zgodnie z definicją, <hr> jest elementem samodzielnym, co oznacza, że nie wymaga znacznika zamykającego. Jest to zgodne z zasadami HTML5, które wprowadziły uproszczoną składnię dla wielu elementów. W praktyce <hr> jest używany do wizualnego oddzielania sekcji w dokumencie HTML, co poprawia czytelność i estetykę strony. Na przykład, w artykule internetowym można zastosować <hr> między różnymi sekcjami, aby wskazać zmianę tematu lub podział pomiędzy wprowadzeniem a treścią główną. Zgodność z tym standardem nie tylko ułatwia pracę z kodem, ale również zapewnia lepszą kompatybilność z przeglądarkami i narzędziami dostępu. Warto także zwrócić uwagę, że dobrym zwyczajem jest dodawanie atrybutów klasy lub identyfikatora do tego znacznika w celu dalszej personalizacji stylów CSS, co zwiększa elastyczność w projektowaniu graficznym strony.
Odtwarzaj przebieg egzaminu krok po kroku i ucz się na własnych błędach. Widzisz dokładnie, w jakiej kolejności rozwiązywałeś pytania, ile czasu spędziłeś nad każdym z nich i kiedy zmieniałeś odpowiedzi.
Co znajdziesz na stronie przebiegu:
Suwak czasu
Przesuwaj i przeglądaj pytania w kolejności, w jakiej je rozwiązywałeś
Tryb nauki
Włącz, aby zobaczyć poprawne odpowiedzi i wyjaśnienia do pytań
Analiza czasu
Sprawdź, ile czasu spędziłeś nad każdym pytaniem i gdzie traciłeś czas
Monitoring focusu
Widzisz momenty, gdy opuściłeś zakładkę — tak jak widzi to nauczyciel
Strona wykorzystuje pliki cookies do poprawy doświadczenia użytkownika oraz analizy ruchu. Szczegóły
Polityka plików cookies
Czym są pliki cookies?
Cookies to małe pliki tekstowe, które są zapisywane na urządzeniu użytkownika podczas przeglądania stron internetowych. Służą one do zapamiętywania preferencji, śledzenia zachowań użytkowników oraz poprawy funkcjonalności serwisu.
Jakie cookies wykorzystujemy?
Niezbędne cookies - konieczne do prawidłowego działania strony
Funkcjonalne cookies - umożliwiające zapamiętanie wybranych ustawień (np. wybrany motyw)
Analityczne cookies - pozwalające zbierać informacje o sposobie korzystania ze strony
Jak długo przechowujemy cookies?
Pliki cookies wykorzystywane w naszym serwisie mogą być sesyjne (usuwane po zamknięciu przeglądarki) lub stałe (pozostają na urządzeniu przez określony czas).
Jak zarządzać cookies?
Możesz zarządzać ustawieniami plików cookies w swojej przeglądarce internetowej. Większość przeglądarek domyślnie dopuszcza przechowywanie plików cookies, ale możliwe jest również całkowite zablokowanie tych plików lub usunięcie wybranych z nich.