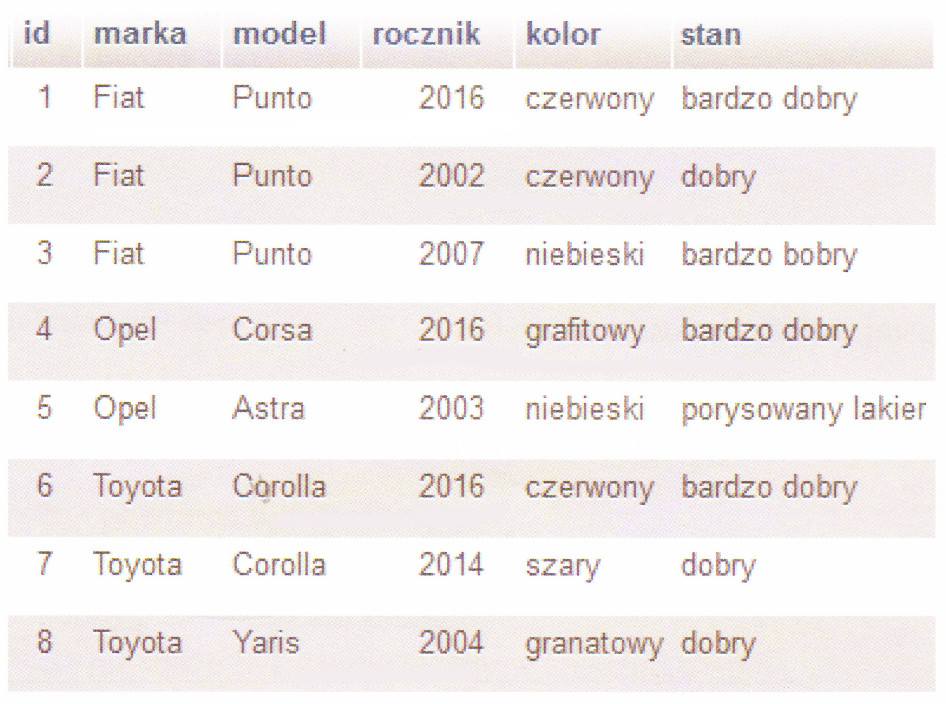
Pytanie 1
Jeżeli zmienna $x zawiera dowolną dodatnią liczbę naturalną, to przedstawiony kod źródłowy PHP ma na celu wyświetlenie:
$licznik = 0; while ($licznik != $x) { echo $licznik; $licznik++; }
A. kolejnych liczb od x do 0
B. liczb wprowadzanych z klawiatury, aż do momentu wprowadzenia wartości x
C. kolejnych liczb od 0 do x-1
D. losowych liczb z zakresu (0, x)
Odpowiedzi błędne wynikają z niepoprawnej interpretacji działania pętli i warunku zakończenia. Pierwszym błędnym rozumowaniem jest wniosek że pętla wyświetla kolejne liczby wstecz od x do 0. W kodzie $licznik jest inkrementowany co oznacza że wartości rosną a nie maleją. To często spotykany błąd gdyż może się wydawać że warunek różności sugeruje zbliżanie się do zera zamiast do wartości $x. Kolejnym błędnym założeniem jest błędne zrozumienie że kod wczytuje wartości z wejścia aż do osiągnięcia $x. Kod nie używa funkcji do wczytywania danych od użytkownika takich jak np. fgets() w związku z czym nie można tutaj mówić o interakcji z użytkownikiem. Ostatnia błędna odpowiedź sugeruje losowanie liczb co jest nieprawidłowe gdyż w kodzie nie występuje żaden mechanizm generowania liczb losowych np. poprzez rand(). Warto tutaj zauważyć że pętla while jest jedną z podstawowych struktur sterujących i zrozumienie jej poprawnego działania jest kluczowe dla programowania w każdym języku. Dobór odpowiedniego warunku zakończenia i modyfikacji zmiennej kontrolnej to podstawy które pomagają uniknąć błędów logicznych w kodzie.