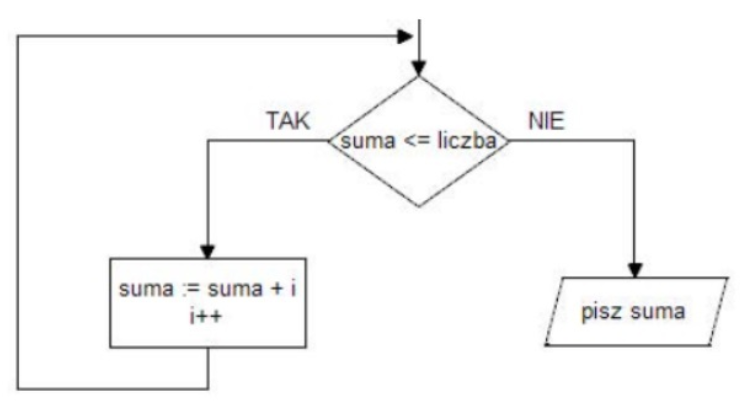
Pytanie 1
Jakie wartości może przyjąć zmienna typu boolean?
A. trzy dowolne liczby naturalne
B. true, false
C. O oraz każdą liczbę całkowitą
D. 1, -1
Zmienna typu logicznego (boolowskiego) w językach programowania, takich jak C++, Java czy Python, może przyjmować tylko dwie wartości: true (prawda) oraz false (fałsz). Te wartości są fundamentalne w logice komputerowej, ponieważ umożliwiają podejmowanie decyzji oraz kontrolowanie przepływu programu poprzez struktury warunkowe, takie jak instrukcje if, while czy for. Na przykład, w języku Python, tworząc zmienną logiczną, możemy użyć operatorów porównania, aby określić, czy dwie wartości są równe: is_equal = (5 == 5), co ustawia is_equal na true. Zmienne logiczne są zdefiniowane w standardach programowania, takich jak IEEE 754 dla reprezentacji liczb zmiennoprzecinkowych, gdzie wartość logiczna jest kluczowa dla operacji porównawczych. Dobrze zrozumiana logika boolowska jest niezbędna dla programistów, ponieważ stanowi podstawę algorytmu decyzyjnego oraz wpływa na efektywność kodu.