Pytanie 1
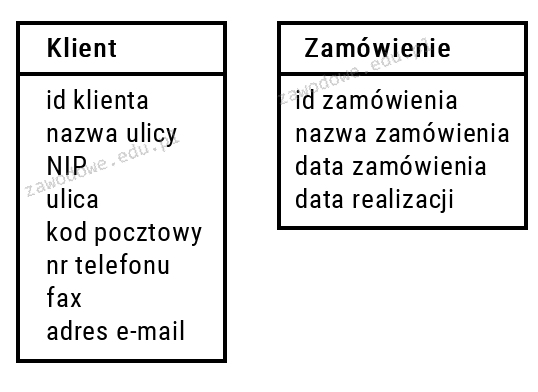
Systemem zarządzania wersjami w projekcie oprogramowania, który jest rozproszony, jest
A. GIT
B. FileZilla
C. TotalCommander
D. Eclipse
Eclipse to zintegrowane środowisko programistyczne (IDE), które wspiera rozwój aplikacji, jednak nie jest systemem kontroli wersji. Jego głównym celem jest ułatwienie pisania, testowania i debugowania kodu, a nie zarządzanie wersjami plików źródłowych. Eclipse oferuje również wtyczki, które mogą integrować się z systemami kontroli wersji, ale sama w sobie nie pełni tej funkcji. FileZilla to program kliencki do przesyłania plików, który działa na zasadzie protokołu FTP. Został zaprojektowany do przesyłania plików między komputerem a serwerem internetowym, a jego funkcje nie obejmują zarządzania wersjami kodu. FileZilla nie śledzi zmian w plikach ani nie umożliwia współpracy nad kodem, co czyni go nieodpowiednim narzędziem w kontekście kontroli wersji. TotalCommander to menedżer plików, który pozwala na zarządzanie plikami i folderami na lokalnym komputerze, jednak nie jest to narzędzie do kontroli wersji. Jego funkcje koncentrują się na operacjach na plikach, takich jak kopiowanie, przenoszenie czy usuwanie, a nie na śledzeniu historii zmian w projektach programistycznych. W skrócie, ani Eclipse, ani FileZilla, ani TotalCommander nie spełniają kryteriów systemu kontroli wersji, co czyni GIT jedynym właściwym wyborem w tej kategorii.