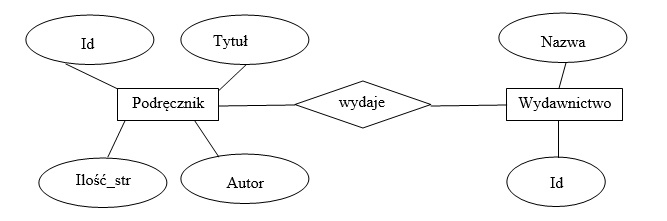
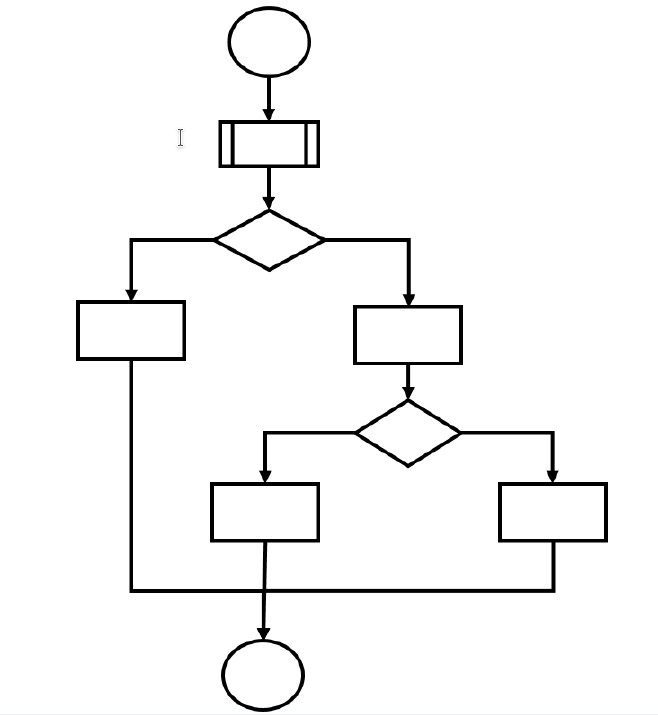
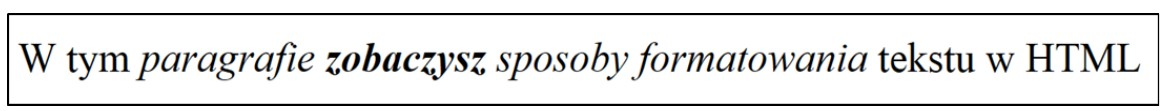Pytanie 1
Jakie jest zadanie funkcji agregującej AVG w zapytaniu?
SELECT AVG(cena) FROM uslugi;
A. obliczyć średnią arytmetyczną wartości wszystkich usług
B. sprawdzić, ile usług znajduje się w tabeli
C. określić najwyższą wartość spośród cen usług
D. zliczyć całkowity koszt wszystkich usług
Funkcja AVG w SQL jest jednym z podstawowych narzędzi do analizy danych w bazach danych. Jej głównym celem jest obliczenie średniej arytmetycznej wartości w kolumnie, co jest kluczowe w raportowaniu i analizie danych. W zapytaniu SQL SELECT AVG(cena) FROM uslugi; funkcja AVG jest użyta, aby uzyskać średnią cenę wszystkich usług zapisanych w tabeli uslugi. Taka średnia jest przydatna w wielu kontekstach biznesowych na przykład przy tworzeniu raportów finansowych czy analizie kosztów w celu optymalizacji oferty. Średnia arytmetyczna pozwala zrozumieć przeciętną wartość danego zestawu danych co jest istotne w podejmowaniu decyzji. Standardy branżowe zalecają użycie funkcji AVG wszędzie tam gdzie potrzebna jest szybka i efektywna analiza danych liczbowych. Zrozumienie działania funkcji AVG jest kluczowe w pracy z bazami danych SQL gdyż pozwala na bardziej złożone analizy jak np. porównanie średnich z różnych okresów czasu lub segmentów rynku.