Odtwarzaj przebieg egzaminu krok po kroku i ucz się na własnych błędach. Widzisz dokładnie, w jakiej kolejności rozwiązywałeś pytania, ile czasu spędziłeś nad każdym z nich i kiedy zmieniałeś odpowiedzi.
Co znajdziesz na stronie przebiegu:
Suwak czasu
Przesuwaj i przeglądaj pytania w kolejności, w jakiej je rozwiązywałeś
Tryb nauki
Włącz, aby zobaczyć poprawne odpowiedzi i wyjaśnienia do pytań
Analiza czasu
Sprawdź, ile czasu spędziłeś nad każdym pytaniem i gdzie traciłeś czas
Monitoring focusu
Widzisz momenty, gdy opuściłeś zakładkę - tak jak widzi to nauczyciel
Jaki opis dotyczy metody POST służącej do przesyłania formularza?
A. Jest zalecana, gdy przesyłane są dane wrażliwe, na przykład hasło, numer telefonu czy numer karty kredytowej
B. Ma dodatkowe ograniczenia związane z długością URL - maksymalnie 255 znaków
C. Dane są przesyłane przez URL, co czyni je widocznymi dla użytkownika
D. Może być dodana jako zakładka w przeglądarce internetowej
Metoda POST jest jedną z dwóch najpopularniejszych metod przesyłania danych w protokole HTTP, obok metody GET. W przeciwieństwie do GET, dane przesyłane za pomocą POST nie są widoczne w adresie URL, co czyni ją bardziej odpowiednią do przesyłania informacji poufnych, takich jak hasła, numery kart kredytowych czy dane osobowe. Dzięki temu, że POST umieszcza dane w ciele żądania HTTP, nie ma ograniczenia długości, które ma miejsce przy GET, co oznacza, że można przesyłać znacznie większe ilości danych. Przykładowe zastosowanie metody POST to formularze rejestracyjne i logowania na stronach internetowych, gdzie bezpieczeństwo użytkownika jest kluczowe. W praktyce, wiele aplikacji webowych korzysta z POST do przesyłania danych do serwera, a dane te mogą być następnie przetwarzane lub zapisywane w bazie danych. Warto również zwrócić uwagę na standardy bezpieczeństwa, takie jak użycie HTTPS, które szyfruje dane przesyłane przy użyciu POST, zwiększając ochronę przed podsłuchiwaniem.
Pytanie 2
W języku HTML, aby uzyskać efekt podobny do tego w przykładzie, trzeba użyć konstrukcji
A. <p><strike>Duży tekst</strike> zwykły tekst</p>
B. <p><strike>Duży tekst zwykły tekst</p>
C. <p><big>Duży tekst</p> zwykły tekst
D. <p><big>Duży tekst</big> zwykły tekst</p>
Odpowiedź jest prawidłowa, ponieważ w języku HTML, aby zwiększyć rozmiar czcionki dla części tekstu, można użyć znacznika <big>. Znacznik ten powoduje, że tekst wewnątrz jest wyświetlany w większym rozmiarze niż tekst otaczający. Jest to przydatne w sytuacjach, gdy chcemy wyróżnić część tekstu bez stosowania zaawansowanego stylu CSS. Chociaż <big> jest uznawany za przestarzały w nowoczesnym HTML, dla celów edukacyjnych i zgodności z starszymi dokumentami HTML wciąż może być stosowany. Praktyką zalecaną w aktualnych standardach jest używanie stylów CSS, np. poprzez przypisanie klasy lub bezpośrednie stylowanie in-line. Warto zaznaczyć, że stosowanie <big> nie jest zalecane w nowych projektach, ponieważ CSS oferuje większą elastyczność i kontrolę nad wyglądem tekstu. Niemniej jednak, znajomość takich znaczników jak <big> pomaga w zrozumieniu, jak rozwijał się HTML i jakie są różnice między starszymi a nowoczesnymi metodami formatowania tekstu.
Pytanie 3
Jaką klauzulę należy użyć w instrukcji CREATE TABLE w SQL, żeby pole rekordu nie mogło być puste?
A. NULL
B. NOT NULL
C. CHECK
D. DEFAULT
Klauzula NOT NULL w poleceniu CREATE TABLE języka SQL służy do zapewnienia, że dane w danym polu rekordu nie mogą być puste. To oznacza, że podczas wstawiania nowych rekordów do tabeli, każde pole, które zostało zdefiniowane z tą klauzulą, musi zawierać wartość. Na przykład, jeśli mamy tabelę pracowników, w której kolumna 'nazwisko' jest zdefiniowana jako NOT NULL, to każde dodanie nowego pracownika do tej tabeli musi zawierać wartość w kolumnie 'nazwisko'. W praktyce jest to bardzo ważne, ponieważ pozwala na utrzymanie integralności danych i zapobiega sytuacjom, w których kluczowe informacje mogłyby zostać pominięte. Użycie NOT NULL jest zgodne z dobrymi praktykami projektowania baz danych, które podkreślają znaczenie pełnych i kompletnych danych. Zastosowanie tej klauzuli zwiększa jakość danych oraz ułatwia późniejsze operacje na tabeli, takie jak zapytania czy raporty.
Pytanie 4
Które ze znaczników HTML umożliwią wyświetlenie na stronie tekstu w jednym wierszu, jeżeli żadne formatowanie CSS nie zostało zdefiniowane?
Dobre strony mojej strony
A. <p>Dobre strony </p><p style=”letter-spacing:3px”>mojej strony</p>
B. <div>Dobre strony </div><div style=”letter-spacing:3px”>mojej strony</div>
C. <span>Dobre strony </span><span style=”letter-spacing:3px”>mojej strony</span>
D. <h3>Dobre strony </h3><h3 style=”letter-spacing:3px”>mojej strony</h3>
Gratulacje, Twoja odpowiedź jest prawidłowa. Wybrałeś znacznik <span>, który jest znacznikiem liniowym w HTML. Znaczniki liniowe nie zaczynają nowego wiersza po swoim zakończeniu, co oznacza, że tekst zawarty w kolejnych znacznikach <span> będzie wyświetlany w jednym wierszu, o ile nie zdefiniowano inaczej za pomocą CSS. Jest to bardzo ważne, kiedy chcemy utworzyć strukturę strony, która nie zależy od domyślnych formatowań. Przykładowo, używając <span>, możemy skonstruować skomplikowane layouty, które są niemożliwe do osiągnięcia za pomocą samych znaczników blokowych. Pamiętaj jednak, że odpowiednie stosowanie znaczników liniowych i blokowych jest ważnym elementem tworzenia semantycznie poprawnych stron internetowych, co może pomóc w poprawie SEO i dostępności Twojej strony.
Pytanie 5
Kolor zapisany w systemie RGB, o wartościach rgb(255,128,16), jaki będzie miał odpowiednik w kodzie szesnastkowym?
A. #ff8010
B. #ff0f10
C. #008010
D. #ff8011
Odpowiedzi, które nie są poprawne, można analizować pod kątem błędów w konwersji wartości RGB na format szesnastkowy. W pierwszym przypadku, kolor zapisany jako #008010 nie odpowiada podanym wartościom RGB, ponieważ składowa czerwonego ma wartość 0 zamiast 255, co sprawia, że kolor ten jest odcieniem zieleni, a nie pomarańczowym. Kolejną niepoprawną odpowiedzią jest #ff0f10, w której składowa zielona wynosi 0, zamiast 128. W efekcie otrzymujemy kolor dominujący w czerwieni z odrobiną niebieskiego, co nie odpowiada oryginalnemu kolorowi. Ostatnia niepoprawna odpowiedź, #ff8011, różni się jedynie w ostatniej cyfrze od poprawnej odpowiedzi. Zwiększenie wartości niebieskiej do 11 zamiast 10 prowadzi do niewłaściwego odcienia, ponieważ zmienia balans kolorów i nie odwzorowuje oryginalnego koloru RGB. Wszystkie te błędy ilustrują znaczenie dokładności w konwersji wartości kolorów, co jest kluczowe w projektowaniu graficznym i webowym.
Pytanie 6
Jaką integralność określa przytoczona definicja?
A. Semantyczną
B. Statyczną
C. Encji
D. Referencyjną
Integralność encji odnosi się do unikalności danych w tabeli poprzez klucze główne. Jest to fundamentalna koncepcja w relacyjnych bazach danych polegająca na tym że każda encja czyli rekord w tabeli musi być jednoznacznie identyfikowalna. Klucz główny zapewnia tę unikalność co jest niezależne od relacji między tabelami opisywanych przez integralność referencyjną. Pojęcie integralności statycznej odnosi się do stanu danych który nie zmienia się w czasie co nie jest bezpośrednio związane z relacjami pomiędzy tabelami. Integralność statyczna może odnosić się do historycznych danych lub archiwów gdzie dane muszą pozostać niezmienne po ich zarejestrowaniu. Podczas gdy integralność referencyjna dotyczy dynamicznych relacji między różnymi zestawami danych integralność statyczna wiąże się z zachowaniem niezmienności danych w obrębie pojedynczego zbioru. Integralność semantyczna odnosi się natomiast do znaczenia i logiki biznesowej danych. Chodzi o zapewnienie że dane w bazie są zgodne z regułami i założeniami biznesowymi. Na przykład data urodzenia nie może być późniejsza niż data zatrudnienia. Chociaż integralność semantyczna jest ważna dla poprawności danych z punktu widzenia aplikacji biznesowej nie opisuje ona relacji między tabelami w taki sposób jak integralność referencyjna. Właściwe rozumienie tych różnych koncepcji jest kluczowe dla projektowania i utrzymania spójnych i niezawodnych systemów baz danych.
Pytanie 7
Wskaż właściwą sekwencję faz projektowania relacyjnej bazy danych?
A. Selekcja, Określenie relacji, Określenie kluczy podstawowych tabel, Określenie zbioru danych
B. Określenie zbioru danych, Selekcja, Określenie kluczy podstawowych tabel, Określenie relacji
C. Określenie kluczy podstawowych tabel, Określenie zbioru danych, Selekcja, Określenie relacji
D. Określenie relacji, Określenie kluczy podstawowych, Selekcja, Określenie zbioru danych
Projektowanie relacyjnej bazy danych to naprawdę ciekawe, ale też skomplikowane zadanie. Na początku trzeba dobrze pomyśleć, jakie dane będziemy gromadzić i w jakiej formie, bo to później zdeterminuje wszystko. Potem wybieramy atrybuty, które są naprawdę istotne dla naszych potrzeb. Kluczowe w tym wszystkim jest ustalenie kluczy podstawowych dla tabel, bo one pomagają jednoznacznie zidentyfikować każdy rekord. Na końcu przychodzi czas na ustalanie relacji między tabelami, co pozwala nam na sensowne powiązanie danych. To wszystko w zgodzie z zasadami projektowania baz danych, które mówią o normalizacji i wydajności. Na przykład, jeśli projektujemy bazę danych dla uczelni, musimy dokładnie wiedzieć, jakie dane o studentach i kursach są dla nas ważne, żeby wszystko działało jak należy.
Pytanie 8
Kod źródłowy przedstawiony poniżej ma na celu wyświetlenie
A. losowych liczb od 0 do 100, aż do wylosowania wartości 0
B. ciągu liczb od 1 do 100
C. liczb wprowadzonych z klawiatury, aż do momentu wprowadzenia wartości 0
D. wylosowanych liczb z zakresu od 1 do 99
Kod źródłowy przedstawiony w pytaniu inicjuje losowanie liczb w przedziale od 0 do 100 i wyświetla je na ekranie aż do momentu wylosowania liczby 0. Taki sposób działania jest możliwy dzięki zastosowaniu pętli while która wykonuje się dopóki warunek w niej zawarty jest spełniony. W tym przypadku warunek ten to różność zmiennej liczba od zera. Funkcja rand(0 100) generuje losowe liczby całkowite z zadanego przedziału. W momencie wylosowania wartości 0 pętla przestaje się wykonywać co skutkuje zakończeniem procesu wyświetlania liczb na ekranie. Tego typu pętle są często używane w programowaniu do tworzenia losowych zdarzeń np. w grach komputerowych gdzie potrzebne jest dynamiczne generowanie wartości. Warto zwrócić uwagę na to że funkcja rand jest standardową funkcją w wielu językach programowania pozwalającą na generowanie losowych liczb co jest przydatne w testowaniu algorytmów w różnych warunkach. Praktyka ta wspomaga proces nauki i doskonalenia umiejętności programistycznych dzięki możliwości symulacji losowych scenariuszy.
Pytanie 9
Jakim znacznikiem można wprowadzić listę numerowaną (uporządkowaną) w dokumencie HTML?
A. <li>
B. <dl>
C. <ol>
D. <ul>
Znacznik <ol> służy do wstawiania list numerowanych (uporządkowanych) w dokumentach HTML. Jego zastosowanie pozwala na tworzenie list, gdzie każdy element jest automatycznie numerowany, co jest szczególnie przydatne w sytuacjach, gdy kolejność elementów ma znaczenie, na przykład w przepisach kulinarnych, instrukcjach czy krokach do wykonania. Warto pamiętać, że elementy listy umieszczane są w znaczniku <li>, który określa każdy pojedynczy wpis na liście. Stosowanie znaczników zgodnych z zaleceniami W3C zapewnia, że strona jest zgodna z zasadami dostępności oraz ułatwia interpretację treści przez wyszukiwarki. Przykład użycia: <ol><li>Krok pierwszy</li><li>Krok drugi</li></ol>, co wygeneruje numerowaną listę z dwoma krokami. Przestrzeganie standardów oraz dobrych praktyk w tworzeniu struktury HTML jest kluczowe dla zapewnienia przejrzystości i efektywności strony internetowej.
Pytanie 10
Jak określa się podzbiór strukturalnego języka zapytań, który dotyczy formułowania zapytań do bazy danych przy użyciu polecenia SELECT?
A. SQL DQL (ang. Data Query Language)
B. SQL DCL (ang. Data Control Language)
C. SQL DML (ang. Data Manipulation Language)
D. SQL DDL (ang. Data Definition Language)
SQL DQL, czyli Data Query Language, to podzbiór języka SQL, który służy do formułowania zapytań do baz danych. Jego główną funkcją jest umożliwienie użytkownikom pobierania danych z tabel w bazie danych przy użyciu polecenia SELECT. Dzięki DQL możliwe jest nie tylko wybieranie konkretnych danych, ale również ich filtrowanie, sortowanie oraz agregowanie. Przykładowo, zapytanie SELECT * FROM pracownicy WHERE dział='IT' zwraca wszystkie dane pracowników z działu IT. DQL jest kluczowym elementem w pracy z bazami danych, ponieważ pozwala na wykorzystanie danych w aplikacjach i systemach informatycznych. Wiedza o DQL jest niezbędna dla każdego, kto zajmuje się analizą danych oraz ich przetwarzaniem. Dobrze skonstruowane zapytania DQL mogą znacznie poprawić wydajność systemów bazodanowych, dlatego warto stosować najlepsze praktyki, takie jak optymalizacja zapytań oraz używanie indeksów, aby zminimalizować czas odpowiedzi i obciążenie serwera.
Pytanie 11
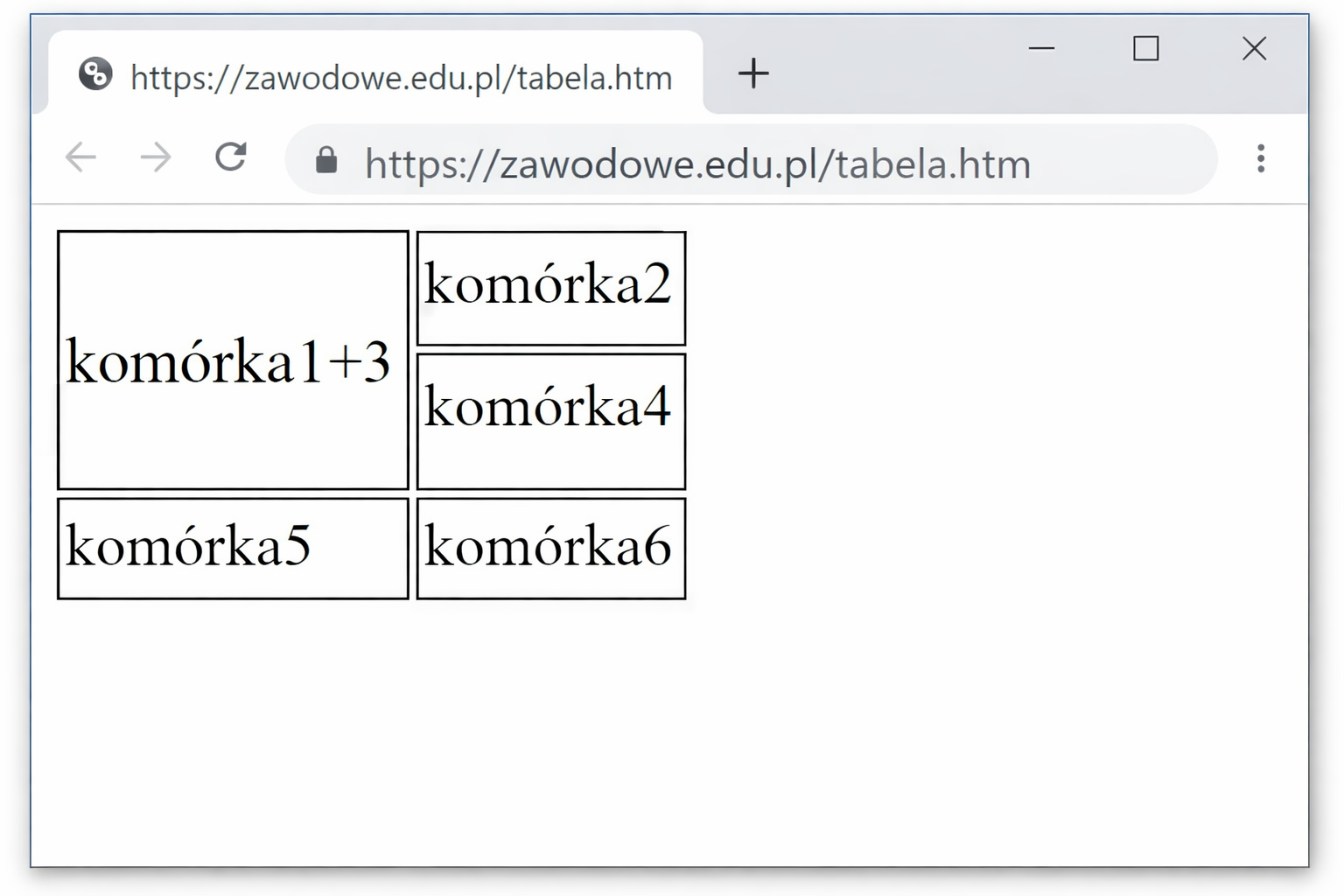
Który fragment definicji dwukolumnowej tabeli odpowiada efektowi scalenia komórki 1 i 3, przedstawionemu na ilustracji?
A. <td rowspan="3">komórka1+3</td>
B. <td colspan="3">komórka1+3</td>
C. <td colspan="2">komórka1+3</td>
D. <td rowspan="2">komórka1+3</td>
W tym zadaniu kluczowe jest rozróżnienie dwóch atrybutów HTML: colspan i rowspan. Oba służą do scalania komórek w tabeli, ale działają w zupełnie różnych kierunkach. Colspan łączy komórki w poziomie, czyli wzdłuż kolumn, natomiast rowspan scala komórki w pionie, wzdłuż wierszy. Na ilustracji widać, że „komórka1+3” zajmuje całą pierwszą kolumnę w dwóch pierwszych wierszach. To oznacza, że jedna komórka rozciąga się na dwa wiersze, a nie na dwie kolumny. Stąd logicznie wynika, że użycie colspan w ogóle nie pasuje do tej sytuacji. Gdybyśmy wpisali <td colspan="2">, przeglądarka potraktowałaby tę komórkę jako rozciągającą się na dwie kolumny w jednym wierszu. Efekt byłby taki, że komórki z drugiej kolumny zostałyby przesunięte, a układ z obrazka zupełnie by się rozjechał. Z kolei wartość colspan="3" w dwukolumnowej tabeli jest po prostu nielogiczna: próbujemy zająć trzy kolumny, gdy istnieją tylko dwie. W praktyce takie nadmiarowe wartości często kończą się chaotycznym renderowaniem tabeli, bo przeglądarka stara się „naprawić” błędny kod. Zostaje jeszcze rowspan z wartością 3. To też nie pasuje do przykładu, bo nasza scalona komórka obejmuje tylko dwa wiersze, nie trzy. Ustawienie rowspan="3" spowodowałoby, że komórka próbowałaby zająć miejsce również w trzecim wierszu, co zaburzyłoby pozycję „komórki5”. Typowym błędem myślowym jest mylenie liczby kolumn z liczbą wierszy: wiele osób patrzy na liczbę pól, które wizualnie wydają się połączone, i automatycznie wybiera colspan, bo kojarzy im się to z „większą szerokością”. Tymczasem trzeba zawsze zadać sobie jedno proste pytanie: czy komórka ma być szersza (więcej kolumn – colspan), czy wyższa (więcej wierszy – rowspan). W tym zadaniu odpowiedź jest jednoznaczna: chodzi o połączenie komórek pionowo w dół, więc poprawne może być tylko rowspan z wartością równą liczbie wierszy, które faktycznie zajmuje scalona komórka, czyli 2.
Pytanie 12
W skrypcie JavaScript, aby uzyskać dane od użytkownika, można wykorzystać okno wyświetlane przez funkcję
A. confirm()
B. alert()
C. prompt()
D. documet.write()
Funkcja prompt() w JavaScript jest specjalnie zaprojektowana do pobierania danych od użytkownika i wyświetlania okna dialogowego, które pozwala wprowadzić tekst. W przeciwieństwie do alert(), który jedynie wyświetla informacje, prompt() umożliwia użytkownikowi wprowadzenie danych, które mogą być później wykorzystane w kodzie. Na przykład, można zainicjować zmienną i przypisać do niej wartość wprowadzaną przez użytkownika: var imie = prompt('Podaj swoje imię:');. Tego rodzaju interakcje są niezwykle ważne w dynamicznych aplikacjach internetowych, gdzie potrzeba elastyczności i użytkownika jako aktywnego uczestnika w procesie. Dobrą praktyką jest zapewnienie, że zapytania są jasne i zrozumiałe, a także, że walidujemy dane wejściowe, aby uniknąć błędów. Warto również mieć na uwadze, że z uwagi na estetykę i funkcjonalność, w nowoczesnym podejściu do interakcji użytkownika, lepszym rozwiązaniem mogą być formularze HTML z JavaScript, które oferują większą kontrolę nad danymi i lepsze możliwości stylizacji."
Pytanie 13
Z tabeli należy wybrać imiona osób, które spełniają kryterium, że drugą literą jest 'e', a słowo ma co najmniej 5 znaków (pięć lub więcej znaków). W tym celu w klauzuli WHERE można użyć wyrażenia
A. imie LIKE '%e%'
B. imie LIKE '_e___%' (po literze e trzy podkreślniki)
C. imie LIKE '_e_%'
D. imie LIKE '_e___' (po literze e trzy podkreślniki)
Odpowiedź 4 jest poprawna, ponieważ stosuje wyrażenie LIKE w sposób, który precyzyjnie spełnia zadany warunek. Wyrażenie '_e___%' wskazuje, że imię musi mieć co najmniej pięć znaków, gdzie 'e' jest drugą literą. Podkreślnik '_' pełni rolę symbolu zastępczego dla pojedynczego znaku, więc '_e___' oznacza, że przed literą 'e' może znajdować się jeden dowolny znak, a po niej co najmniej trzy znaki. Znak '%' na końcu oznacza, że po tych pięciu znakach mogą występować dodatkowe znaki, co jest zgodne z wymogiem, aby długość imienia wynosiła co najmniej pięć znaków. Przykłady zastosowania tego wyrażenia obejmują zapytania do baz danych, gdzie chcemy uzyskać imiona takie jak 'Marek', 'Tereska' czy 'Petrus'. Tego rodzaju zapytania są zgodne z dobrymi praktykami SQL, które podkreślają znaczenie precyzyjnych warunków wyszukiwania dla optymalizacji i ograniczenia zbiorów danych, co przekłada się na większą efektywność operacji. W kontekście projektowania baz danych, stosowanie takich precyzyjnych kryteriów w zapytaniach jest kluczowe dla zapewnienia szybkości i efektywności systemów bazodanowych, co jest istotne w dzisiejszych zastosowaniach biznesowych, gdzie czas odpowiedzi jest niezwykle ważny.
Pytanie 14
Funkcją w PHP, która służy do tworzenia ciasteczek, jest
A. echocokie()
B. createcookie()
C. addcokie()
D. setcookie()
Funkcja setcookie() w języku PHP jest kluczowym narzędziem do zarządzania ciasteczkami (cookies) na poziomie serwera. Umożliwia ona tworzenie i konfigurowanie ciasteczek, które następnie są przesyłane do przeglądarki użytkownika. Ciasteczka są używane do przechowywania informacji o sesji, preferencjach użytkownika oraz danych śledzących. Funkcja setcookie() przyjmuje kilka argumentów, w tym nazwę ciasteczka, jego wartość, czas wygaśnięcia (w postaci znacznika czasowego), ścieżkę, domenę oraz flagi bezpieczeństwa. Przykładowe użycie funkcji może wyglądać następująco: setcookie('user', 'John Doe', time() + 86400, '/'); co tworzy ciasteczko o nazwie 'user', z wartością 'John Doe', które wygasa po jednym dniu. Ważne jest, aby zwrócić uwagę, że funkcja ta musi być wywoływana przed jakimkolwiek wysyłaniem nagłówków HTTP, co oznacza, że należy ją umieścić na początku skryptu PHP. Również, aby znacząco poprawić bezpieczeństwo, warto korzystać z flagi HttpOnly, aby zminimalizować ryzyko ataków XSS. Zastosowanie setcookie() w odpowiedni sposób przyczynia się do poprawy doświadczeń użytkowników oraz zwiększa funkcjonalność aplikacji internetowych.
Pytanie 15
Błędy w interpretacji kodu PHP są rejestrowane
A. w dzienniku zdarzeń systemu Windows
B. pomijane przez przeglądarkę oraz interpreter PHP
C. w oknie edytora, w którym tworzony jest kod PHP
D. w logu, o ile odpowiedni parametr jest ustawiony w pliku php.ini
Odpowiedzi, które sugerują inne metody zapisywania błędów interpretacji kodu PHP, są niepoprawne z kilku powodów. Po pierwsze, chociaż system Windows oferuje podgląd zdarzeń, nie jest on wykorzystywany do rejestrowania błędów PHP. PHP działa w swoim własnym kontekście, a wszelkie błędy są specyficzne dla tego języka i jego środowiska uruchomieniowego, a nie dla systemu operacyjnego. Po drugie, zapis błędów w oknie edytora, w którym powstaje kod PHP, jest praktyką niewłaściwą. Edytory kodu, chociaż mogą oferować funkcje podpowiedzi i analizy błędów na żywo, nie są odpowiednie do rejestrowania błędów wykonania, które mogą wystąpić w trakcie działania skryptów. To podejście ograniczałoby również możliwości analizy błędów, które mogą być istotne w późniejszym etapie prac nad projektem. Ostatnia z przedstawionych odpowiedzi, mówiąca o ignorowaniu błędów przez przeglądarkę oraz interpreter PHP, jest niezgodna z zasadami działania PHP. Interpreter PHP zawsze przetwarza błędy, a ich ignorowanie mogłoby prowadzić do poważnych problemów w działaniu aplikacji. Właściwą praktyką jest nie tylko rejestrowanie błędów, ale także ich odpowiednia obsługa, aby zapewnić stabilność i bezpieczeństwo aplikacji.
Pytanie 16
Jakie uprawnienia są wymagane do tworzenia i przywracania kopii zapasowej bazy danych Microsoft SQL Server 2005 Express?
A. Administrator systemu.
B. Użytkownicy.
C. Użytkownik lokalny.
D. Użytkownicy zabezpieczeń.
Aby wykonać i odtworzyć kopię zapasową bazy danych w Microsoft SQL Server 2005 Express, użytkownik musi posiadać uprawnienia administratora systemu. To oznacza, że ma on pełne prawo do zarządzania bazami danych, w tym do wykonywania operacji takich jak tworzenie kopii zapasowych oraz ich przywracanie. Administrator systemu może także konfigurować ustawienia serwera, zarządzać dostępem innych użytkowników oraz monitorować wydajność bazy danych. Przykładem praktycznym może być sytuacja, w której administrator wykonuje regularne kopie zapasowe, aby zabezpieczyć dane przed ich utratą spowodowaną awarią sprzętu lub błędami użytkowników. Warto również zauważyć, że zgodnie z najlepszymi praktykami IT, regularne tworzenie kopii zapasowych jest kluczowe dla zapewnienia bezpieczeństwa danych, a także zgodności z regulacjami prawnymi dotyczącymi ochrony danych. Uprawnienia te są zgodne z ogólnymi standardami zarządzania bazami danych, które podkreślają znaczenie odpowiednich ról użytkowników w kontekście bezpieczeństwa i integralności danych.
Pytanie 17
Polecenie GRANT w języku SQL służy do
A. odbierania użytkownikom praw do obiektów.
B. nadawania użytkownikom praw do obiektów.
C. umieszczania nowych danych w bazie.
D. aktualizacji istniejących danych w bazie.
Poprawnie – polecenie GRANT w SQL służy właśnie do nadawania użytkownikom praw do obiektów w bazie danych. W praktyce GRANT jest jednym z kluczowych narzędzi mechanizmu kontroli dostępu, czyli tzw. autoryzacji. Najpierw ktoś łączy się z bazą (to jest uwierzytelnianie – login/hasło, certyfikat itd.), a dopiero potem baza sprawdza, jakie uprawnienia ma ten użytkownik. I tu wchodzi GRANT. Administrator lub właściciel obiektu może przyznać użytkownikowi np. prawo SELECT do tabeli `klienci`, prawo INSERT do tabeli `zamowienia`, albo prawo EXECUTE do procedury składowanej. Składnia jest dość prosta, np.: `GRANT SELECT, INSERT ON klienci TO jan;`. W większości systemów (np. PostgreSQL, Oracle, MySQL/MariaDB, SQL Server) idea jest podobna, różnią się tylko szczegóły i nazwy ról czy typów uprawnień. W dobrych praktykach bezpieczeństwa nie daje się użytkownikom uprawnień typu „wszystko na wszystkim”, tylko dokładnie to, czego potrzebują (tzw. zasada najmniejszych uprawnień – least privilege). Moim zdaniem warto już na etapie nauki SQL odróżniać polecenia do pracy na danych (SELECT, INSERT, UPDATE, DELETE) od poleceń do zarządzania uprawnieniami, takich jak GRANT i REVOKE. W codziennej pracy administratora baz, programisty backendu czy nawet osoby od DevOps, GRANT pojawia się bardzo często: przy tworzeniu nowych kont aplikacyjnych, przy separacji środowisk (dev/test/prod), przy ograniczaniu dostępu do wrażliwych tabel, np. z danymi osobowymi. Dobre zrozumienie GRANT pomaga też szybko diagnozować błędy typu „permission denied” i świadomie projektować politykę bezpieczeństwa w systemie.
Pytanie 18
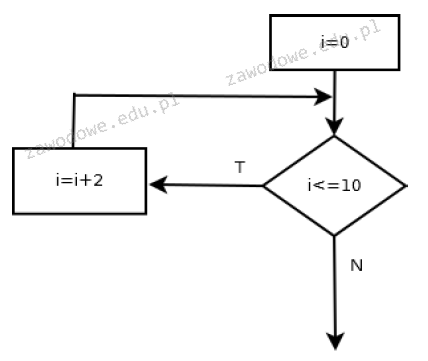
Algorytm pokazany na ilustracji można zapisać w języku JavaScript przy użyciu instrukcji
A. var i = 0; while(i <= 10) i += 2
B. var i = 0; do i = i + 2; while(i < 10)
C. for(i = 0; i > 10; i++)
D. var i = 0; do i++; while(i > 10)
Odpowiedź var i = 0 while(i <= 10) i += 2; jest poprawna, ponieważ reprezentuje poprawną implementację pętli while w języku JavaScript, która odzwierciedla logikę przedstawioną na rysunku. Kluczowym elementem jest inicjalizacja zmiennej i, ustawiając ją na 0. Następnie pętla while jest używana do sprawdzenia warunku i <= 10, co oznacza, że dopóki ten warunek jest spełniony, blok pętli będzie wykonywany. W każdym cyklu wartość i jest zwiększana o 2 za pomocą wyrażenia i += 2. Jest to typowy sposób iteracji w JavaScript, który pozwala na kontrolowaną manipulację zmienną kontrolującą pętlę. Takie podejście jest zgodne z najlepszymi praktykami, ponieważ zapewnia przejrzystość kodu i łatwość jego późniejszej modyfikacji. W praktycznych zastosowaniach, takie struktury są często używane w sytuacjach, gdy potrzebujemy przetworzyć dane w określonym zakresie, np. iterując przez elementy tablicy co drugi element. Zastosowanie pętli while z odpowiednim warunkiem umożliwia precyzyjną kontrolę nad przebiegiem iteracji, co jest kluczowe w programowaniu aplikacji i skryptów.
Pytanie 19
Które zapytanie języka SQL zlicza wszystkie rekordy w tabeli Zamowienia?
A. SELECT COUNT(*) FROM Zamowienia;
B. SELECT ALL(*) FROM Zamowienia;
C. COUNT(Zamowienia);
D. SELECT SUM() FROM Zamowienia;
Prawidłowe zapytanie to: SELECT COUNT(*) FROM Zamowienia;. Funkcja agregująca COUNT() w SQL służy właśnie do zliczania rekordów, a gwiazdka * oznacza „wszystkie kolumny”, czyli w praktyce każdy wiersz w tabeli. Silnik bazy danych nie patrzy wtedy na konkretne pola, tylko sprawdza ile wierszy spełnia warunek w klauzuli FROM/WHERE. To jest standardowy zapis opisany w dokumentacji większości systemów bazodanowych, takich jak MySQL, PostgreSQL, SQL Server czy Oracle. Moim zdaniem warto od razu zapamiętać ten wzorzec, bo jest używany dosłownie wszędzie: do paginacji wyników w aplikacjach webowych (np. policzenie ile jest wszystkich zamówień, żeby wyświetlić numer strony), do raportów (ile zamówień w danym miesiącu), do monitoringu (ile rekordów ma tabela po imporcie danych) itd. Bardzo często łączy się COUNT(*) z klauzulą WHERE, np.: SELECT COUNT(*) FROM Zamowienia WHERE status = 'zrealizowane'; – wtedy zliczasz tylko wybrane zamówienia, spełniające warunek. Dobra praktyka jest też taka, że jeśli chcesz policzyć wszystkie wiersze, to używasz właśnie COUNT(*), a nie COUNT(nazwa_kolumny), bo COUNT(kolumny) pomija wartości NULL. To czasem jest pożądane, ale domyślnie, przy zwykłym „ile jest rekordów w tabeli”, stosuje się COUNT(*). W wielu optymalizacjach baz danych silnik ma specjalne mechanizmy, które potrafią bardzo szybko policzyć COUNT(*) bez czytania całej tabeli, co jest kolejnym powodem, żeby korzystać z tej formy, zgodnie z dobrą praktyką branżową.
Pytanie 20
Który typ danych obsługiwany przez PHP jest przeznaczony do obsługi zmiennych typu logicznego?
A. Float
B. Integer
C. String
D. Boolean
Odpowiedź "Boolean" jest prawidłowa, ponieważ jest to typ danych w języku PHP, który jest używany do przechowywania zmiennych logicznych. Zmienne tego typu mogą mieć jedynie dwie wartości: true (prawda) lub false (fałsz). Jest to niezwykle istotne w programowaniu, ponieważ umożliwia podejmowanie decyzji na podstawie warunków. Przykładowo, w konstrukcjach warunkowych, takich jak if, można sprawdzić, czy zmienna logiczna jest prawdziwa, co pozwala na wykonanie określonej akcji. Warto również zauważyć, że w PHP można łatwo konwertować inne typy danych na typ boolean za pomocą operatorów, takich jak ! (negacja) oraz porównań, co jest zgodne z zasadami dobrych praktyk programistycznych. Używanie typów logicznych jest kluczowe w kontekście programowania obiektowego oraz podczas pracy z strukturami danych. Przykład: $isAvailable = true; if ($isAvailable) { echo 'Produkt jest dostępny.'; }.
Pytanie 21
Efekt przedstawiony w filmie powinien być zdefiniowany w selektorze
A. tr:hover { background-color: Pink; }
B. tr:active { background-color: Pink; }
C. tr { background-color: Pink; }
D. td, th { background-color: Pink; }
Poprawny selektor to tr:hover { background-color: Pink; }, bo dokładnie opisuje sytuację pokazaną na filmie: efekt pojawia się dopiero po najechaniu kursorem na cały wiersz tabeli. Pseudo-klasa :hover w CSS służy właśnie do definiowania stylów w momencie, gdy użytkownik „najeżdża” myszką na dany element. Jeśli więc chcemy, żeby podświetlał się cały rząd tabeli, logiczne i zgodne z dobrymi praktykami jest przypięcie efektu do znacznika tr, a nie do pojedynczych komórek. W praktyce taki zapis stosuje się bardzo często w interfejsach webowych: w panelach administracyjnych, listach zamówień, tabelach z uczniami, produktami, logami systemowymi itd. Dzięki temu użytkownik łatwiej śledzi, który wiersz właśnie ogląda. To niby detal, ale z punktu widzenia UX robi sporą różnicę. Z mojego doświadczenia to jeden z tych prostych trików CSS, które od razu poprawiają „odczuwalną” jakość strony. Ważne jest też to, że :hover jest częścią standardu CSS (opisane m.in. w specyfikacji CSS Selectors Level 3/4) i działa w praktycznie wszystkich współczesnych przeglądarkach. Nie trzeba do tego żadnego JavaScriptu, żadnych skomplikowanych skryptów – czysty CSS. Dobrą praktyką jest również używanie bardziej stonowanych kolorów niż Pink w prawdziwych projektach, np. #f5f5f5 albo lekki odcień niebieskiego, tak żeby kontrast był czytelny i nie męczył wzroku. Warto też pamiętać, że podobny mechanizm możesz zastosować na innych elementach: np. a:hover dla linków, button:hover dla przycisków czy nawet div:hover dla całych kafelków w layoutach. Kluczowe jest to, żeby pseudo-klasa :hover była przypięta dokładnie do tego elementu, który ma reagować na interakcję użytkownika.
Pytanie 22
Jakie czynniki wpływają na wysokość dźwięku?
A. częstotliwość drgań fali akustycznej
B. czas oscylacji źródła dźwięku
C. metoda wzbudzania drgań
D. intensywność wzbudzenia drgań
Częstotliwość drgań fali akustycznej to taki kluczowy element, który wpływa na to, jak wysoko brzmi dźwięk. Mówiąc prosto, to ilość drgań, które źródło dźwięku wykonuje w danym czasie, zwykle mierzona w Hertzach (Hz). Im wyższa ta częstotliwość, tym wyższy dźwięk wydobywają instrumenty muzyczne. Na przykład na gitarze, jak skrócisz strunę, to dźwięk staje się wyższy, co jest zgodne z tym, co mówi fizyka akustyczna. W inżynierii dźwięku często korzysta się z filtrów i equalizerów, żeby odpowiednio dostosować dźwięki w nagraniach. Rozumienie tego jest ważne nie tylko w muzyce, ale i w technologiach audio. Projektanci dźwięku muszą dobrze znać te zasady, aby móc stworzyć odpowiednie efekty dźwiękowe. Więc, ogólnie mówiąc, znajomość tego, jak częstotliwość wiąże się z wysokością dźwięku, jest istotna dla każdej osoby związanej z dźwiękiem, zarówno w teorii, jak i w praktyce.
Pytanie 23
Jaki typ powinien być wykorzystany, aby pole danych mogło przyjmować liczby zmiennoprzecinkowe?
A. CHAR
B. VARCHAR
C. INT
D. FLOAT
Typ danych FLOAT jest idealnym rozwiązaniem do przechowywania liczb rzeczywistych, ponieważ umożliwia reprezentację wartości z przecinkiem dziesiętnym. W przeciwieństwie do typu INT, który obsługuje jedynie liczby całkowite, FLOAT potrafi przechowywać znacznie szerszy zakres wartości, w tym liczby z miejscami po przecinku. Użycie typu FLOAT jest szczególnie korzystne w aplikacjach wymagających precyzyjnych obliczeń, takich jak kalkulatory, systemy finansowe czy analizy danych. Przykładowo, w systemach baz danych SQL, definiując kolumnę jako FLOAT, możemy przechowywać wartości takie jak 3.14, -0.001 lub 2.71828. Standard SQL określa, że FLOAT może posiadać różne precyzje, co pozwala na dostosowanie pamięci do potrzeb konkretnej aplikacji. W praktyce, FLOAT jest wykorzystywany w złożonych obliczeniach inżynieryjnych, gdzie precyzyjne wartości są kluczowe dla wyników obliczeń.
Pytanie 24
Który z typów danych w C++ oferuje najszerszy zakres wartości?
A. long int
B. long long
C. int
D. short
Typ danych 'long long' w języku C++ jest często używany do przechowywania dużych liczb całkowitych. W standardzie C++11 i późniejszych, 'long long' jest gwarantowanym typem danych, który może pomieścić co najmniej 64 bity, co pozwala na przechowywanie wartości w zakresie od -9 223 372 036 854 775 808 do 9 223 372 036 854 775 807. Jest to znaczące w kontekście obliczeń, gdzie mogą występować duże liczby, na przykład w aplikacjach finansowych, przetwarzaniu danych lub obliczeniach naukowych. Korzystanie z tego typu danych jest zgodne z dobrymi praktykami programistycznymi, ponieważ pozwala na unikanie przepełnienia zmiennej, co może prowadzić do nieprzewidywalnych wyników. Warto również zauważyć, że w przypadku używania dużych wartości, należy zwrócić uwagę na właściwe zarządzanie pamięcią oraz wydajnością aplikacji. Przykładem zastosowania 'long long' może być program do obliczania faktorialu dużych liczb, gdzie standardowe typy danych mogłyby nie wystarczyć. Zastosowanie 'long long' zapewnia większą elastyczność w obliczeniach i zwiększa bezpieczeństwo kodu.
Pytanie 25
Jakie dane zostaną wybrane po wykonaniu poniższej kwerendy na pokazanych rekordach?
SELECTidFROMsamochodyWHERErocznikLIKE"2%4";
id
marka
model
rocznik
1
Fiat
Punto
2016
2
Fiat
Punto
2002
3
Fiat
Punto
2007
4
Opel
Corsa
2016
5
Opel
Astra
2003
6
Toyota
Corolla
2016
7
Toyota
Corolla
2014
8
Toyota
Yaris
2004
A. Pole id równe 7 oraz 8
B. Brak danych
C. Tylko id równe 8
D. Wszystkie id
Odpowiedź jest prawidłowa, ponieważ zapytanie SQL SELECT id FROM samochody WHERE rocznik LIKE '2_4'; filtruje rekordy, które mają w kolumnie rocznik wartość z drugą cyfrą równą '2' i czwartą cyfrą równą '4'. W złożonym zapytaniu SQL zastosowano operator LIKE z użyciem symbolu podkreślenia (_) jako symbolu zastępczego dla pojedynczego znaku. To oznacza, że szukamy dowolnego roku, który zaczyna się od cyfry '2', ma dowolną cyfrę na drugiej pozycji i cyfrę '4' na ostatniej pozycji. Praktycznie oznacza to, że wybierane są identyfikatory pojazdów, które mają rocznik odpowiadający temu wzorcowi. W dostarczonym zbiorze danych tylko rekordy o id 7 i 8 spełniają ten warunek, ponieważ rocznik to 2014 i 2004. Tego rodzaju konstrukcja SQL jest użyteczna w sytuacjach, gdy potrzebujemy selektywnie uzyskać dane na podstawie wzorców. Operator LIKE jest bardzo efektywny w analizie danych tekstowych w bazach danych np. w raportach analitycznych gdzie kluczowe jest wyszukiwanie na podstawie wzorców. Warto zaznaczyć, że takie podejście jest zgodne ze standardami SQL, ułatwiającymi zarządzanie i filtrowanie danych w złożonych systemach bazodanowych.
GRANT SELECT, INSERT, UPDATE, DELETE ON klienci TO adam@localhost
A. do manipulowania danymi bazy danych klienci
B. do zarządzania strukturą bazy danych klienci
C. do manipulowania danymi w tabeli klienci
D. do zarządzania strukturą tabeli klienci
Pozostałe opcje wskazują na zarządzanie strukturą bazy danych lub tabeli co w kontekście podanego polecenia SQL nie jest prawidłowe Zarządzanie strukturą bazy danych odnosi się do operacji takich jak tworzenie usuwanie lub modyfikowanie tabel indeksów i innych obiektów bazy danych Przykłady takich operacji to polecenia CREATE ALTER i DROP które zmieniają definicję strukturalną tabel lub innych obiektów bazodanowych W przypadku zarządzania strukturą tabeli moglibyśmy mówić o dodawaniu nowych kolumn zmienianiu typu danych istniejących kolumn czy zmianach w kluczach indeksach Tego typu zmiany nie są objęte poleceniem GRANT SELECT INSERT UPDATE DELETE które koncentruje się wyłącznie na manipulacji danymi w istniejącej strukturze Dlatego też typowym błędem myślowym jest utożsamianie operacji na danych z operacjami modyfikującymi strukturę bazy danych takimi jak dodawanie tabel czy kolumn Operatorzy SQL są precyzyjnie zdefiniowani i rozdzieleni na kategorie manipulacji danymi DML oraz definicji danych DDL co jest kluczowym rozróżnieniem w pracy z bazami danych
Pytanie 27
W kodzie źródłowym zapisanym w języku HTML wskaż błąd walidacji dotyczący tego fragmentu: ```
CSS
Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący ...```
A. Znacznik zamykający /b niezgodny z zasadą zagnieżdżania.
B. Nieznany znacznik h6.
C. Znacznik br nie może występować wewnątrz znacznika p.
D. Znacznik br nie został poprawnie zamknięty.
Twoja odpowiedź jest poprawna. Znacznik zamykający /b w badanym kodzie HTML jest niezgodny z zasadą zagnieżdżania. Zasada ta mówi, że znaczniki powinny być zamykane w odwrotnej kolejności do otwierania - zgodnie z modelem LIFO (Last In, First Out). W praktyce oznacza to, że jeśli otworzyliśmy na przykład najpierw znacznik <i>, a następnie <b>, to najpierw powinniśmy zamknąć <b>, a dopiero potem <i>. Nieprzestrzeganie tej zasady może prowadzić do nieoczekiwanych wyników podczas renderowania strony. Jest to istotne dla utrzymania czytelności i prawidłowego funkcjonowania kodu. W codziennej praktyce, szczególnie w większych projektach, stosowanie się do takich zasad pomaga utrzymać kod zrozumiałym i łatwym do zarządzania.
Pytanie 28
Jaką wiadomość należy umieścić w przedstawionym fragmencie kodu PHP zamiast znaków zapytania? $a=mysql_connect('localhost','adam','mojeHasło'); if(!$a) echo "?????????????????????????";
A. Rekord został pomyślnie dodany do bazy
B. Błąd połączenia z serwerem SQL
C. Błąd w przetwarzaniu zapytania SQL
D. Wybrana baza danych nie istnieje
W sytuacji, gdy nie udaje się nawiązać połączenia z serwerem baz danych MySQL, komunikat błędu powinien jasno wskazywać na problem związany z połączeniem. W kodzie PHP, używając funkcji mysql_connect(), jeśli połączenie się nie powiedzie, zwracany jest błąd, który powinien być odpowiednio obsłużony. W tym przypadku odpowiednia treść komunikatu powinna brzmieć 'Błąd połączenia z serwerem SQL'. Ważne jest, aby programiści dbali o poprawne komunikaty błędów, ponieważ ułatwiają one diagnozowanie problemów. Dobrą praktyką jest także stosowanie obsługi wyjątków, co zwiększa stabilność aplikacji. Przykład: zamiast używać mysql_connect(), zaleca się korzystanie z mysqli lub PDO, które oferują bardziej zaawansowane opcje zarządzania błędami oraz obsługę wyjątków. W przypadku użycia mysqli, mógłbyś to zrobić w następujący sposób: $mysqli = new mysqli('localhost', 'adam', 'mojeHasło'); if ($mysqli->connect_error) { echo 'Błąd połączenia z serwerem SQL: ' . $mysqli->connect_error; } Poprawne raportowanie błędów jest kluczowym elementem programowania, ponieważ pozwala na szybką identyfikację i naprawę potencjalnych problemów.
Pytanie 29
Który z elementów HTML stanowi blokowy znacznik?
A. span
B. p
C. strong
D. img
Znacznik <p> (paragraf) jest klasyfikowany jako element blokowy, co oznacza, że zajmuje całą szerokość dostępnego miejsca w swoim kontenerze i jest renderowany na nowej linii. Elementy blokowe są fundamentalne w układzie strony internetowej, ponieważ pozwalają na strukturalne grupowanie treści w sposób, który jest zrozumiały dla przeglądarek internetowych oraz dla użytkowników. Przykłady użycia elementu <p> obejmują tworzenie akapitów w artykułach, opisów produktów, czy innych dłuższych fragmentów tekstu. Dobre praktyki wskazują, że należy stosować <p> dla tekstu, który ma być wyświetlany jako samodzielny blok, co poprawia czytelność i dostępność treści. Ponadto, zgodnie z wytycznymi W3C, stosowanie znaczników blokowych, takich jak <p>, przyczynia się do lepszej struktury dokumentu HTML oraz ułatwia jego interpretację przez roboty wyszukiwarek, co jest kluczowe w kontekście SEO. Warto również zauważyć, że w CSS można łatwo stylizować znaczniki blokowe, co daje większą kontrolę nad wyglądem i układem strony.
Pytanie 30
Który z kodów PHP sprawi, że zostanie wyświetlona sformatowana data oraz czas ostatnich odwiedzin użytkownika witryny, natomiast podczas pierwszej wizyty nic się nie wyświetli?
Kod 1. echo date('d.m.Y, H:i', $_COOKIE['c1']);
setcookie('c1', time());
Kod 2. if(isset($_COOKIE['c1']))
echo date($_COOKIE['c1']);
setcookie('c1', time(), time() + 30 * 86400);
Kod 3. echo date($_COOKIE['c1']);
setcookie('c1', time(), time() + 30 * 86400);
Kod 4. setcookie('c1', time(), time() + 30 * 86400);
A. Kod 3.
B. Kod 1.
C. Kod 4.
D. Kod 2.
Niepoprawne kody PHP nie spełniają wymagań zadania z różnych powodów. Niektóre nie wykorzystują funkcji isset() do sprawdzenia, czy ciasteczko 'c1' istnieje, co może prowadzić do błędów, jeżeli ciasteczko nie zostało ustawione. Inne zawsze wyświetlają datę i czas ostatnich odwiedzin, nawet jeżeli jest to pierwsza wizyta użytkownika na stronie, co jest niezgodne z treścią pytania. Kolejnym błędnym podejściem jest nieaktualizowanie ciasteczka 'c1' po wyświetleniu daty i czasu ostatnich odwiedzin, co powoduje, że zawsze wyświetlana jest ta sama data i czas. Ważnym elementem pracy z ciasteczkami w PHP jest zrozumienie, jak są one zapisywane i odczytywane, a także jak można je wykorzystać do przechowywania informacji o użytkownikach. Błędy te pokazują brak zrozumienia tych kwestii.
Pytanie 31
Funkcja przedstawiona w kodzie JavaScript ma na celu
A. wyświetlić kolejne liczby od a do n
B. pokazać wynik mnożenia a przez n
C. zwrócić wynik potęgowania an
D. zwrócić iloczyn kolejnych liczb od 1 do a
Funkcja w języku JavaScript przedstawiona w pytaniu wykonuje operację potęgowania poprzez iteracyjne mnożenie liczby a przez siebie n razy. Jest to klasyczny sposób realizacji potęgowania, polegający na zastosowaniu pętli for. W momencie inicjalizacji zmiennej wynik przypisujemy jej wartość 1, co jest typowym sposobem rozpoczęcia mnożenia w algorytmach iteracyjnych. Następnie pętla for iteruje n razy, za każdym razem mnożąc wynik przez a, co odpowiada matematycznemu działaniu a razy a razy a, aż do n razy. Po zakończeniu pętli funkcja zwraca wynik, który jest wartością an. Takie podejście jest stosowane w przypadkach, gdy nie mamy bezpośredniego dostępu do wbudowanych funkcji potęgowania, jak Math.pow, jednak w praktyce, dla lepszej wydajności i czytelności kodu, zaleca się korzystanie z wbudowanych metod. Potęgowanie jest powszechnie stosowane w obliczeniach matematycznych, fizyce oraz w algorytmach wymagających szybkiego przetwarzania dużych ilości danych. Zrozumienie mechaniki działania pętli for i operacji iteracyjnych jest kluczowe w programowaniu, co czyni to pytanie istotnym elementem egzaminu certyfikacyjnego.
Pytanie 32
Jakie są odpowiednie kroki w odpowiedniej kolejności, które należy podjąć, aby nawiązać współpracę pomiędzy aplikacją internetową po stronie serwera a bazą danych SQL?
A. wybór bazy danych, nawiązanie połączenia z serwerem baz danych, zapytanie do bazy - wyświetlane na stronie WWW, zamknięcie połączenia
B. zapytanie do bazy, wybór bazy, wyświetlenie na stronie WWW, zamknięcie połączenia
C. wybór bazy, zapytanie do bazy, nawiązanie połączenia z serwerem baz danych, wyświetlenie na stronie WWW, zamknięcie połączenia
D. nawiązanie połączenia z serwerem baz danych, wybór bazy, zapytanie do bazy - wyświetlane na stronie WWW, zamknięcie połączenia
Analizując niepoprawne odpowiedzi, można zauważyć, że każda z nich zawiera fundamentalne błędy w kolejności operacji. W przypadku pierwszej odpowiedzi, zaczynanie od zapytania do bazy danych bez wcześniejszego nawiązania połączenia z serwerem jest nie tylko niepraktyczne, ale wręcz niemożliwe. System nie jest w stanie wykonać jakiegokolwiek zapytania, jeśli nie istnieje aktywne połączenie, co prowadzi do błędów wykonania. W drugiej odpowiedzi również występuje błąd, polegający na wysyłaniu zapytania przed wybraniem bazy danych. W rzeczywistości, aby system mógł poprawnie zrealizować zapytanie, musi najpierw wiedzieć, z jaką bazą ma do czynienia. Ostatnia z niepoprawnych odpowiedzi, która sugeruje wybór bazy danych przed nawiązaniem połączenia, również jest błędna, ponieważ nie można wybrać bazy bez aktywnego połączenia z serwerem. W praktyce, każda z tych odpowiedzi nie uwzględnia kluczowych zasad dotyczących zarządzania połączeniami z bazami danych, takich jak zasady dotyczące transakcji oraz efektywnego zarządzania zasobami, co jest niezbędne w kontekście wydajnych aplikacji internetowych.
Pytanie 33
Co oznacza jednostka ppi (pixels per inch)?
A. określa rozdzielczości obrazów generowanych przez drukarki i plotery
B. określa rozdzielczość obrazów wektorowych
C. jest parametrem określającym rozdzielczość cyfrowych urządzeń wykonujących pomiary
D. określa rozdzielczość obrazów rastrowych
Jednostka ppi (pixels per inch) opisuje gęstość pikseli, czyli ile pojedynczych punktów obrazu przypada na jeden cal długości. W praktyce oznacza to rozdzielczość obrazów rastrowych, bo grafika rastrowa składa się właśnie z siatki pikseli. Im wyższe ppi, tym więcej informacji szczegółowej na danym obszarze i tym ostrzejszy, bardziej „gładki” obraz na ekranie albo w wydruku. Moim zdaniem warto to sobie wyobrazić jak mozaikę: więcej małych kafelków na tym samym obszarze daje dokładniejszy obraz. W projektowaniu grafiki na potrzeby WWW typową wartością jest 72–96 ppi, bo tyle mniej więcej mają monitory i urządzenia według standardów branżowych. Natomiast do druku przyjmuje się zwykle 300 ppi dla materiałów wysokiej jakości, co wynika z dobrych praktyk poligraficznych. Pamiętaj, że ppi dotyczy pliku rastrowego (np. PNG, JPG, PSD), a nie samej drukarki – drukarki opisuje się parametrem dpi. W pracy grafika, DTP‑owca czy webdesignera właściwe ustawienie ppi jest kluczowe, żeby obraz nie wyszedł rozmazany, ząbkowany albo nienaturalnie przeskalowany. W narzędziach takich jak Photoshop, GIMP czy Affinity Photo zawsze przy tworzeniu nowego dokumentu warto świadomie ustawić ppi odpowiednio do przeznaczenia: ekran, druk, prezentacja multimedialna.
Pytanie 34
Jak można usunąć ciasteczko o nazwie ciastko, korzystając z języka PHP?
A. setcookie("$ciastko", "", 0);
B. unsetcookie("$ciastko");
C. setcookie("ciastko", "", time()-3600);
D. deletecookie("ciastko");
Wszystkie pozostałe odpowiedzi zawierają błędy koncepcyjne, które uniemożliwiają skuteczne usunięcie ciasteczka. Przykładowo, deletecookie("ciastko") to niepoprawne podejście, ponieważ nie istnieje funkcja o takiej nazwie w standardowej bibliotece PHP. Użytkownicy mogą myśleć, że wystarczy wywołać funkcję, która usunie ciasteczko, jednak PHP wymaga korzystania z funkcji setcookie(), aby to osiągnąć. W przypadku setcookie("$ciastko", "", 0), użytkownik próbuje usunąć ciasteczko, ale błędnie ustawia czas wygaśnięcia na zero. Wartość zero nie jest interpretowana jako czas przeszły, co uniemożliwia przeglądarce uznanie ciasteczka za wygasłe. Ponadto, użycie zmiennej "$ciastko" zamiast bezpośredniego odniesienia do nazwy ciasteczka wprowadza dodatkowe zamieszanie. Ostatnia propozycja, unsetcookie("$ciastko"), również jest błędna, ponieważ nie istnieje funkcja unsetcookie() w PHP. Użytkownicy mogą mylnie przypuszczać, że funkcje do usuwania zmiennych i ciasteczek są sobie równe, jednak każda z nich ma swoje specyficzne zastosowanie i zachowanie. Kluczowym punktem w pracy z ciasteczkami jest zrozumienie, że celem jest ich usunięcie przez ustawienie daty wygaśnięcia w przeszłości, a nie przez wywoływanie nieistniejących funkcji.
Pytanie 35
Które z poniższych poleceń przyznaje użytkownikowi uczen najniższy poziom uprawnień w zakresie zmiany danych i struktury tabel?
A. GRANT INSERT, DROP ON szkola.przedmioty TO uczen;
B. GRANT DROP ON szkola.przedmioty TO uczen;
C. GRANT ALTER, SELECT ON szkola.przedmioty TO uczen;
D. GRANT SELECT ON szkola.przedmioty TO uczen;
Rozpatrując inne polecenia, które zostały zaproponowane, należy zauważyć, że każde z nich przyznaje użytkownikowi 'uczen' szerszy zakres uprawnień, co nie jest zgodne z założeniem nadawania minimalnych uprawnień. Przyznanie uprawnień DROP, jak w przypadku polecenia GRANT DROP ON szkola.przedmioty TO uczen, pozwoliłoby użytkownikowi usunąć tabelę 'przedmioty', co jest nieakceptowalne w kontekście użytkownika edukacyjnego. Takie działanie nie tylko zagrażałoby integralności bazy danych, ale również mogłoby prowadzić do utraty ważnych informacji. Podobnie, przyznanie uprawnień INSERT, jak w poleceniu GRANT INSERT, DROP ON szkola.przedmioty TO uczen, umożliwia użytkownikowi dodawanie nowych rekordów do tabeli, co w przypadku ucznia nie jest pożądane, ponieważ jego rola powinna być ograniczona do przeglądania danych. Co więcej, polecenie GRANT ALTER, SELECT ON szkola.przedmioty TO uczen zawiera uprawnienie ALTER, które pozwala na modyfikację struktury tabeli, co również nie powinno mieć miejsca w kontekście użytkownika, który jest tylko uczniem. Wszelkie te niepoprawne podejścia prowadzą do niebezpieczeństwa związane z nieautoryzowanymi zmianami w bazie danych, co jest sprzeczne z najlepszymi praktykami w zakresie zarządzania uprawnieniami i bezpieczeństwa danych. Warto pamiętać, że właściwe zarządzanie uprawnieniami nie tylko zabezpiecza dane, ale również usprawnia procesy edukacyjne, zapewniając odpowiedni dostęp do informacji w sposób kontrolowany.
Pytanie 36
W podanym kodzie JavaScript ponumerowano linie dla ułatwienia. W programie występuje błąd, ponieważ po wykonaniu żadna wiadomość nie jest wyświetlana. Aby usunąć ten błąd, należy
1. if (a < b)
2. document.write(a);
3. document.write(" jest mniejsze");
4. else
5. document.write(b);
6. document.write(" jest mniejsze");
A. dodać nawiasy klamrowe w sekcjach if oraz else
B. w liniach 3 i 6 zamienić znaki cudzysłowu na apostrof, np. ' jest mniejsze'
C. w liniach 2 i 5 zmienne a i b umieścić w cudzysłowach
D. umieścić znaki $ przed nazwami zmiennych
Wstawienie nawiasów klamrowych do sekcji 'if' oraz 'else' jest kluczowe dla prawidłowego działania kodu w JavaScript. Kiedy nie używamy nawiasów klamrowych, język domyślnie interpretuje tylko jedną linię jako część bloku 'if' lub 'else'. W sytuacji, gdy mamy więcej niż jedną operację do wykonania w ramach tego samego warunku, brak nawiasów prowadzi do błędów wykonania. Przykład: jeśli chcemy wyświetlić komunikat oraz wartość zmiennej 'a', musimy objąć te operacje nawiasami klamrowymi. Warto również pamiętać, że korzystanie z nawiasów klamrowych zwiększa czytelność kodu, co jest zgodne z najlepszymi praktykami programistycznymi. Stosowanie tej zasady pozwala unikać niejednoznaczności i potencjalnych błędów w logicznych blokach kodu. Dodatkowo, pomocne jest testowanie kodu w środowiskach, które wyłapują błędy syntaktyczne, co ułatwia wczesne wykrywanie problemów.
Pytanie 37
W CSS, aby określić typ czcionki, powinno się zastosować właściwość
A. font-size
B. font-family
C. font-style
D. font-face
Właściwość 'font-family' w CSS jest kluczowa dla określenia kroju czcionki, który ma być używany na stronie internetowej. Dzięki tej właściwości możemy wskazać jedną lub więcej czcionek, które będą stosowane dla danego elementu. Wartością może być nazwa konkretnej czcionki, na przykład 'Arial', lub rodzina czcionek, jak 'sans-serif'. Przykład użycia to: 'font-family: Arial, sans-serif;'. W przypadku braku dostępności danej czcionki, przeglądarka wybierze następną z listy, co pozwala na zapewnienie spójności i czytelności tekstu na różnych urządzeniach. Zgodnie z najlepszymi praktykami, zaleca się użycie kilku opcji czcionek, aby zapewnić lepszą dostępność. Warto również pamiętać, aby unikać stosowania zbyt wielu różnych krojów czcionek, co mogłoby wpływać negatywnie na estetykę i czytelność strony. Użycie 'font-family' w połączeniu z innymi właściwościami, takimi jak 'font-size' czy 'font-weight', pozwala na pełne dostosowanie wyglądu tekstu zgodnie z wymaganiami projektu.
Pytanie 38
W języku JavaScript stworzono funkcję o nazwie liczba_max, która porównuje trzy liczby naturalne przekazane jako argumenty i zwraca największą z nich. Jak powinno wyglądać prawidłowe wywołanie tej funkcji oraz uzyskanie jej wyniku?
A. liczba_max(a,b,c,wynik);
B. liczba_max(a,b,c)=wynik;
C. var wynik=liczba_max(a,b,c);
D. liczba_max(a,b,c);
Odpowiedź "var wynik=liczba_max(a,b,c);" jest poprawna, ponieważ w ten sposób prawidłowo wywołujemy funkcję liczba_max, przekazując do niej trzy argumenty: a, b oraz c. Funkcja ta ma na celu zwrócenie maksymalnej wartości z przekazanych liczb, więc przypisanie jej wyniku do zmiennej wynik jest logicznym krokiem. W języku JavaScript, operator przypisania (=) pozwala na zdefiniowanie zmiennych, co w tym przypadku oznacza, że zmienna wynik będzie zawierać wartość zwróconą przez funkcję. Wartością tą jest największa liczba spośród a, b i c. Zastosowanie takiego podejścia jest zgodne z koncepcją programowania funkcjonalnego, gdzie funkcje są traktowane jako „pierwszej klasy obywateli”, co oznacza, że można je przypisywać do zmiennych. Dobrą praktyką w programowaniu jest również używanie czytelnych nazw zmiennych oraz funkcji, co ułatwia zrozumienie kodu przez inne osoby. Dodatkowo, warto zwrócić uwagę na typy danych przekazywanych do funkcji, aby uniknąć nieprzewidzianych błędów podczas obliczeń.
Pytanie 39
W językach programowania o układzie strukturalnym, aby przechować dane o 50 uczniach (ich imionach, nazwiskach oraz średniej ocen), konieczne jest zastosowanie
A. struktury z 50 elementami o składowych typu tablicowego
B. tablicy z 50 elementami o składowych strukturalnych
C. tablicy z 50 elementami o składowych typu łańcuchowego
D. klasy z 50 elementami typu tablicowego
Wybór tablicy 50 elementów o składowych strukturalnych jest prawidłowy ze względu na potrzebę przechowywania złożonych danych o uczniach. W tym przypadku, każdy element tablicy powinien reprezentować jednego ucznia i zawierać jego imię, nazwisko oraz średnią ocen. Struktura danych, taka jak struktura, pozwala na grupowanie różnych typów danych w jeden obiekt, co jest zgodne z dobrymi praktykami programowania w językach strukturalnych. Przykładowo, w języku C można zadeklarować strukturę dla ucznia w następujący sposób: `struct Uczen { char imie[50]; char nazwisko[50]; float srednia; };`. Następnie można utworzyć tablicę 50 elementów tej struktury: `struct Uczen uczniowie[50];`. Stosowanie struktur w tym kontekście ułatwia zarządzanie danymi i zwiększa czytelność kodu, co jest szczególnie ważne w przypadku projektów wymagających łatwego dostępu do różnych atrybutów obiektów. Używanie dobrze zdefiniowanych struktur danych jest zgodne z zasadami programowania obiektowego, nawet w językach proceduralnych, i przyczynia się do lepszej organizacji kodu oraz jego skalowalności.
Pytanie 40
Który z poniższych typów plików NIE JEST używany do publikacji grafiki lub animacji na stronach www?
A. AIFF
B. PNG
C. SVG
D. SWF
Wybór formatu plików, które są używane do publikacji grafiki lub animacji na stronach internetowych, jest istotnym elementem projektowania interfejsów. SVG, jako format wektorowy, oferuje wyjątkową elastyczność i skalowalność, co czyni go idealnym dla responsywnych projektów. Jego możliwość dostosowywania w kodzie HTML i CSS sprawia, że jest on często wybierany przez projektantów, którzy dążą do zachowania wysokiej jakości wizualnej bez utraty wydajności. SWF, z kolei, był popularnym formatem dla animacji Flash, który pozwalał na interaktywne elementy w stronach internetowych, jednak obecnie jest mniej używany z powodu rosnącej niekompatybilności z nowoczesnymi przeglądarkami. PNG, jako format rastrowy, zapewnia wsparcie dla przezroczystości oraz wysoką jakość obrazu, co czyni go uniwersalnym narzędziem w publikacji grafiki w internecie. Tak więc, wybór AIFF jako formatu do publikacji byłby błędny, ponieważ nie jest on przeznaczony do przechowywania grafiki ani animacji, a zastosowanie go w tym kontekście może prowadzić do nieporozumień i niewłaściwej prezentacji treści. Ważne jest, aby zrozumieć, że różne formaty plików mają swoje specyficzne przeznaczenie i zalety, co powinno być brane pod uwagę przy tworzeniu zawartości internetowej.
Strona wykorzystuje pliki cookies do poprawy doświadczenia użytkownika oraz analizy ruchu. Szczegóły
Polityka plików cookies
Czym są pliki cookies?
Cookies to małe pliki tekstowe, które są zapisywane na urządzeniu użytkownika podczas przeglądania stron internetowych. Służą one do zapamiętywania preferencji, śledzenia zachowań użytkowników oraz poprawy funkcjonalności serwisu.
Jakie cookies wykorzystujemy?
Niezbędne cookies - konieczne do prawidłowego działania strony
Funkcjonalne cookies - umożliwiające zapamiętanie wybranych ustawień (np. wybrany motyw)
Analityczne cookies - pozwalające zbierać informacje o sposobie korzystania ze strony
Jak długo przechowujemy cookies?
Pliki cookies wykorzystywane w naszym serwisie mogą być sesyjne (usuwane po zamknięciu przeglądarki) lub stałe (pozostają na urządzeniu przez określony czas).
Jak zarządzać cookies?
Możesz zarządzać ustawieniami plików cookies w swojej przeglądarce internetowej. Większość przeglądarek domyślnie dopuszcza przechowywanie plików cookies, ale możliwe jest również całkowite zablokowanie tych plików lub usunięcie wybranych z nich.