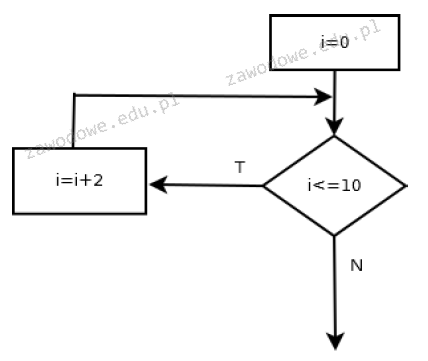
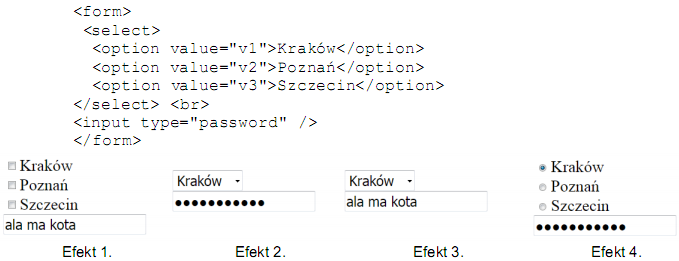
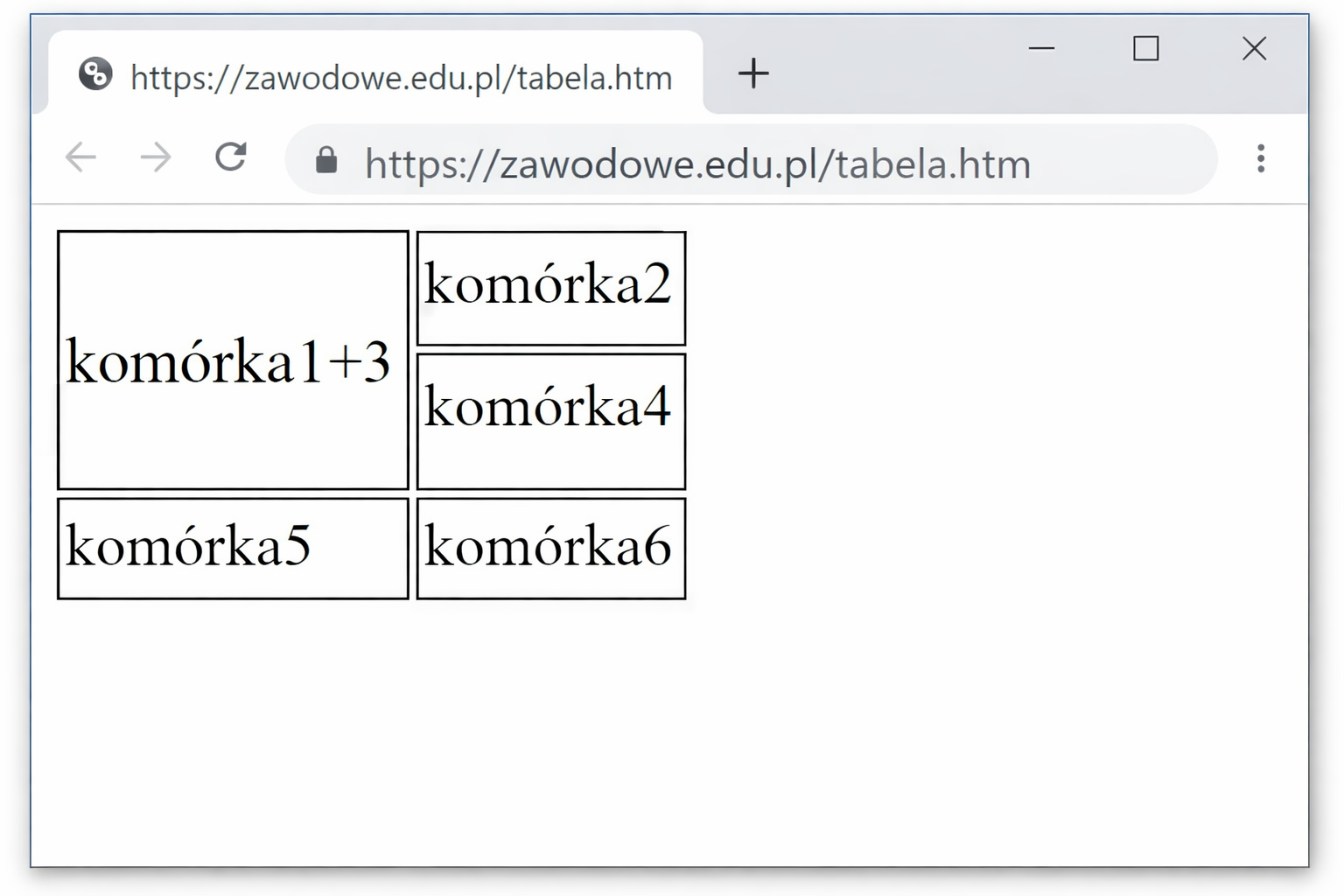
Pytanie 1
Jaką wartość uzyska zmienna x po wykonaniu poniższego kodu PHP?
mysqli_query($db, "DELETE FROM produkty WHERE status < 0"); $x = mysqli_affected_rows($db);
A. Liczbę wierszy przetworzonych przez zapytanie DELETE FROM.
B. Liczbę wierszy w tabeli produkty, dla których pole status przekracza zero.
C. Liczbę wierszy, które znajdują się w bazie danych.
D. Liczbę wierszy, które zostały dodane do tabeli produkty.
Poprawna odpowiedź dotyczy liczby wierszy przetworzonych przez zapytanie DELETE FROM w bazie danych. Funkcja mysqli_affected_rows($db) zwraca liczbę wierszy, które zostały zmodyfikowane przez ostatnie wykonane zapytanie na danym połączeniu z bazą danych. W przypadku zapytania DELETE, zwróci ona liczbę wierszy, które zostały usunięte w wyniku działania tego zapytania. W kontekście dobrych praktyk, zawsze warto sprawdzać, jakie operacje zostały wykonane na bazie danych, aby zrozumieć wpływ zapytań na dane. Na przykład, w aplikacjach e-commerce, przed usunięciem produktów, można wykorzystać tę informację do potwierdzenia, że usunięcie danych nie wpływa negatywnie na inne elementy systemu. Użycie tej funkcji pozwala na efektywne zarządzanie danymi oraz na utrzymanie spójności w bazie danych, co jest kluczowe w kontekście bezpieczeństwa i integralności danych.