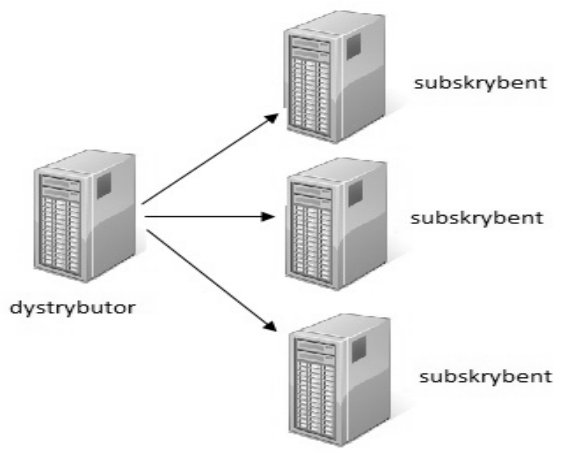
Pytanie 1
W CSS zapis w postaci
h1::first-letter {color: red;} spowoduje, że kolor czerwony zostanie zastosowany do
A. pierwszej linii akapitu
B. tekstu nagłówka w pierwszym stopniu
C. pierwszej litery nagłówka w drugim stopniu
D. pierwszej litery nagłówka w pierwszym stopniu
Zapis <span>h1::first-letter {color: red;} </span> jest w porządku, bo korzysta z pseudoelementu :first-letter, który działa na pierwszą literkę w nagłówku h1. To całkiem fajne, bo możemy w ten sposób stylizować tę pierwszą literę i nadać nagłówkom ciekawszy wygląd. Na przykład, jeśli mamy nagłówek h1 z napisem 'Witaj świecie', to dzięki temu kodowi, litera 'W' zrobi się czerwona. W CSS warto ogarnąć, że :first-letter działa tylko na bloki, takie jak nagłówki czy akapity, więc warto to mieć na uwadze, gdy coś stylizujemy. Używanie pseudoelementów to dobre podejście do tworzenia ładnych i funkcjonalnych interfejsów, a przy okazji daje nam większą kontrolę nad tym, jak wyglądają nasze elementy.