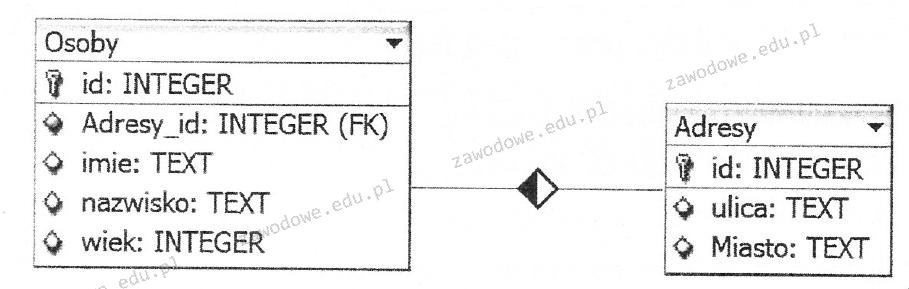
Pytanie 1
Jakiego ograniczenia (constraint) używa się do zdefiniowania klucza obcego?
A. AUTO_INCREMENT(ID)
B. FOREIGN KEY(ID)
C. UNIQUE KEY(ID)
D. PRIMARY KEY(ID)
Odpowiedź 'FOREIGN KEY(ID)' jest poprawna, ponieważ klucz obcy służy do definiowania relacji między tabelami w bazach danych. Klucz obcy to atrybut lub zestaw atrybutów w jednej tabeli, który odnosi się do klucza głównego innej tabeli. Przykładowo, w bazie danych, która obsługuje system zarządzania zamówieniami, tabela 'Zamówienia' może zawierać kolumnę 'KlientID', będącą kluczem obcym odnoszącym się do kolumny 'ID' w tabeli 'Klienci'. Użycie kluczy obcych pozwala na zapewnienie integralności referencyjnej, co oznacza, że każdy wpis w tabeli 'Zamówienia' musi odpowiadać istniejącemu klientowi w tabeli 'Klienci'. Dobrym praktykom w projektowaniu baz danych jest stosowanie kluczy obcych jako sposobu na unikanie niezgodności danych oraz na umożliwienie wykonywania zapytań z wykorzystaniem JOIN, co ułatwia uzyskiwanie skonsolidowanych informacji z różnych tabel. Ponadto, w przypadku usunięcia lub aktualizacji rekordów w tabeli źródłowej, można skonfigurować odpowiednie zasady, takie jak 'CASCADE', które automatycznie zaktualizują powiązane dane w tabeli docelowej, co jest istotne dla zachowania spójności danych.