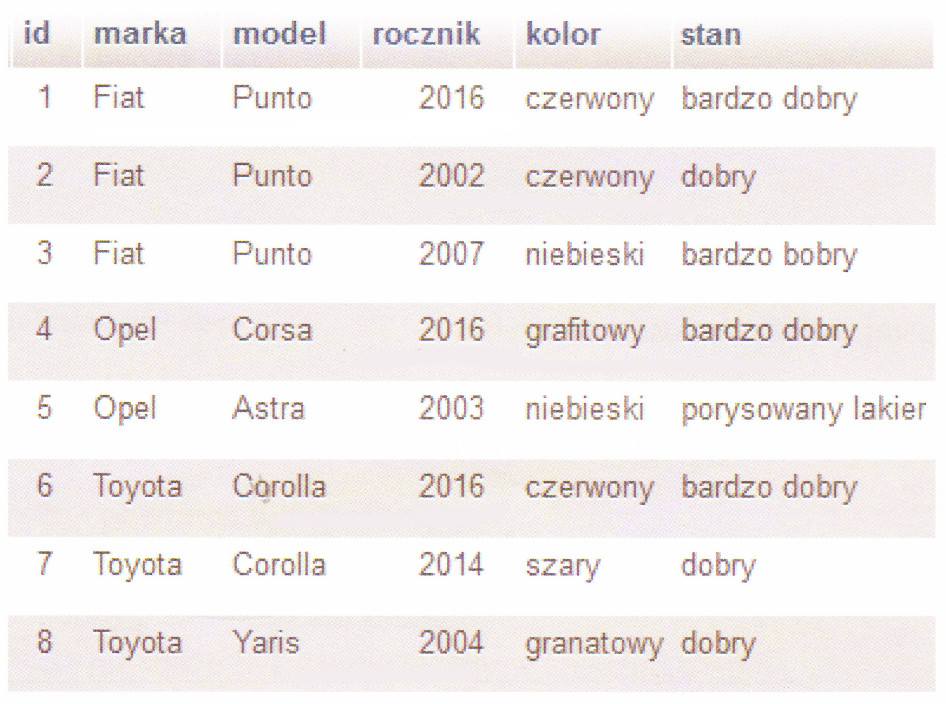
Pytanie 1
Które imiona spełniają warunek
SELECT imie FROM mieszkancy WHERE imie LIKE '_r%';?
A. Gerald, Jarosław, Marek, Tamara
B. Rafał, Rebeka, Renata, Roksana
C. Krzysztof, Krystyna, Romuald
D. Arieta, Krzysztof, Krystyna, Tristan
Wzorzec
'_r%' oznacza: jeden dowolny znak (_), potem litera „r”, potem dowolny ciąg (%) - czyli DRUGĄ literą imienia musi być „r”. Pasują np. Arieta, Krzysztof, Krystyna, Tristan. Dlatego to ten zestaw.