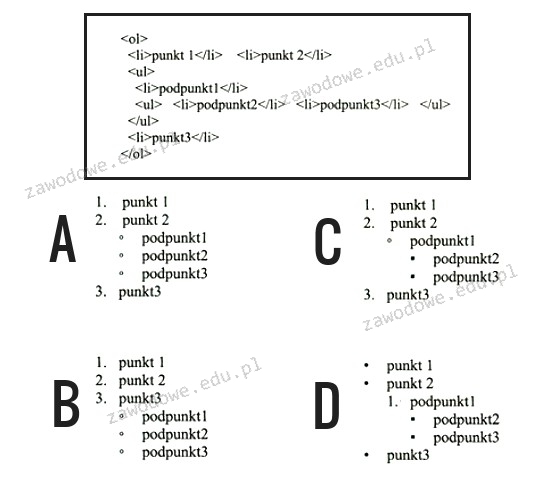
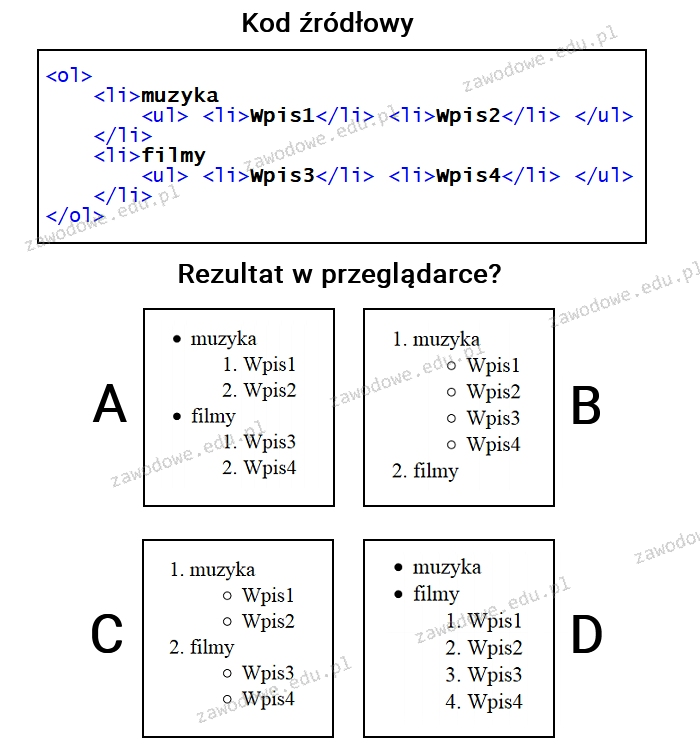
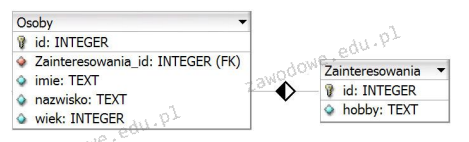
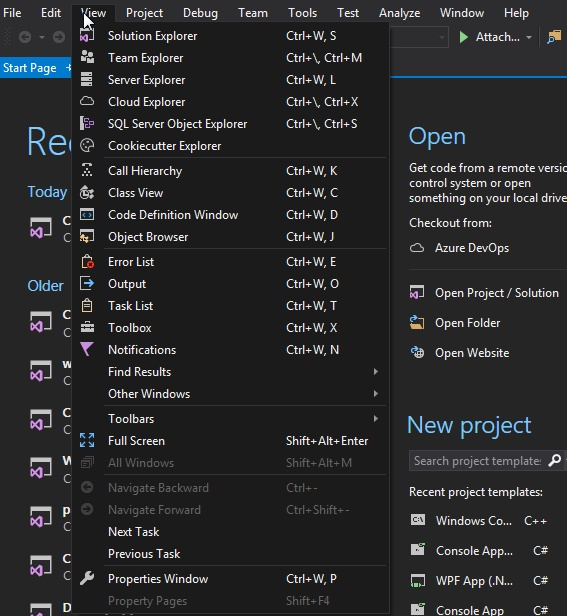
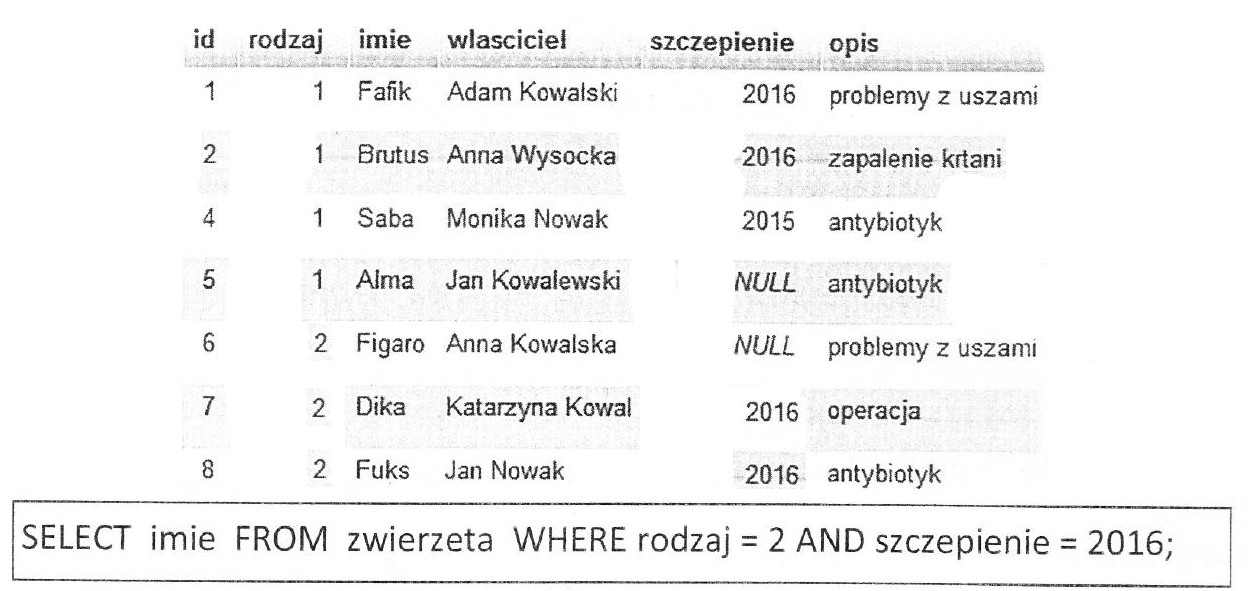
Pytanie 1
Który modyfikator jest związany z opisem podanym poniżej?
| Metoda oraz zmienna jest dostępna wyłącznie dla innych metod własnej klasy. |
A. public
B. protected
C. static
D. private
Modyfikator static to pojęcie związane nie z ograniczaniem dostępu, a z przypisywaniem pola lub metody do samej klasy, a nie instancji obiektu. Użycie static nie wpływa na kontrolę dostępu do metod lub zmiennych z innych klas, jest raczej związane z zarządzaniem pamięcią i odwołaniami. Public z kolei oznacza brak ograniczeń w dostępie, umożliwiając użycie metod i zmiennych przez inne klasy, co jest przeciwieństwem private. Public sprawia, że elementy klasy są dostępne dla wszystkich, co może prowadzić do niezamierzonych zmian i trudności w utrzymaniu kodu szczególnie w dużych systemach. Protected to modyfikator pozwalający na dostęp do elementów klasy jedynie klasom dziedziczącym i znajdującym się w tym samym pakiecie (w Java). Jest przydatny w dziedziczeniu, ale nie ogranicza dostępu tak jak private. Typowym błędem jest mylenie static i public z mechanizmami ochrony danych, podczas gdy odnoszą się one do innych aspektów zarządzania klasami. Static dotyczy współdzielenia danych w obrębie klasy, a public szerokiego dostępu. Wybór odpowiedniego modyfikatora dostępu jak private jest kluczowy dla implementacji enkapsulacji, co jest fundamentem bezpieczeństwa i elastyczności w programowaniu obiektowym. Static i public to koncepcje o różnym zastosowaniu, niekoniecznie związane z ochroną i ukrywaniem danych przed dostępem zewnętrznym.