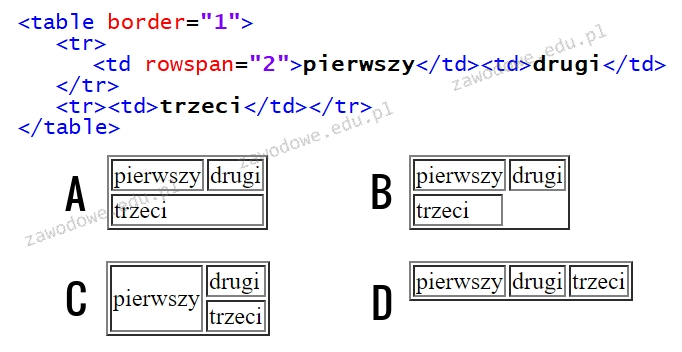
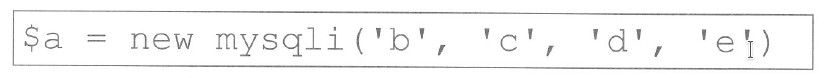Pytanie 1
Jakie oprogramowanie do zarządzania treścią umożliwia proste tworzenie oraz aktualizację witryny internetowej?
A. PHP
B. CMS
C. SQL
D. CSS
Wybór SQL, PHP i CSS jako odpowiedzi na pytanie o system zarządzania treścią jest wynikiem nieporozumienia dotyczącego funkcji i zastosowań tych technologii. SQL (Structured Query Language) jest językiem zapytań służącym do komunikacji z bazami danych. Umożliwia on tworzenie, modyfikowanie oraz pobieranie danych, co jest kluczowe dla działania wielu aplikacji internetowych, w tym CMS-ów, lecz sam w sobie nie dostarcza interfejsu do zarządzania treścią. PHP to język skryptowy, często wykorzystywany do tworzenia dynamicznych aplikacji webowych. Choć PHP jest podstawą wielu systemów CMS, to sam język nie jest narzędziem do zarządzania treściami. CSS (Cascading Style Sheets) natomiast jest językiem stylizacji, który odpowiada za wygląd i układ strony, ale nie wprowadza funkcji zarządzania treścią. Zastanawiając się nad tymi technologiami, można zauważyć, że mylenie ich z CMS-em może wynikać z braku zrozumienia ich ról w ekosystemie webowym. Każda z tych technologii odgrywa istotną rolę w budowie i funkcjonowaniu stron internetowych, ale nie są one systemami do zarządzania treścią. Prawidłowe zrozumienie ich funkcji jest kluczem do efektywnego wykorzystania ich w praktyce.