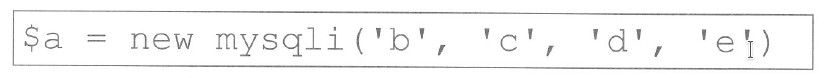Pytanie 1
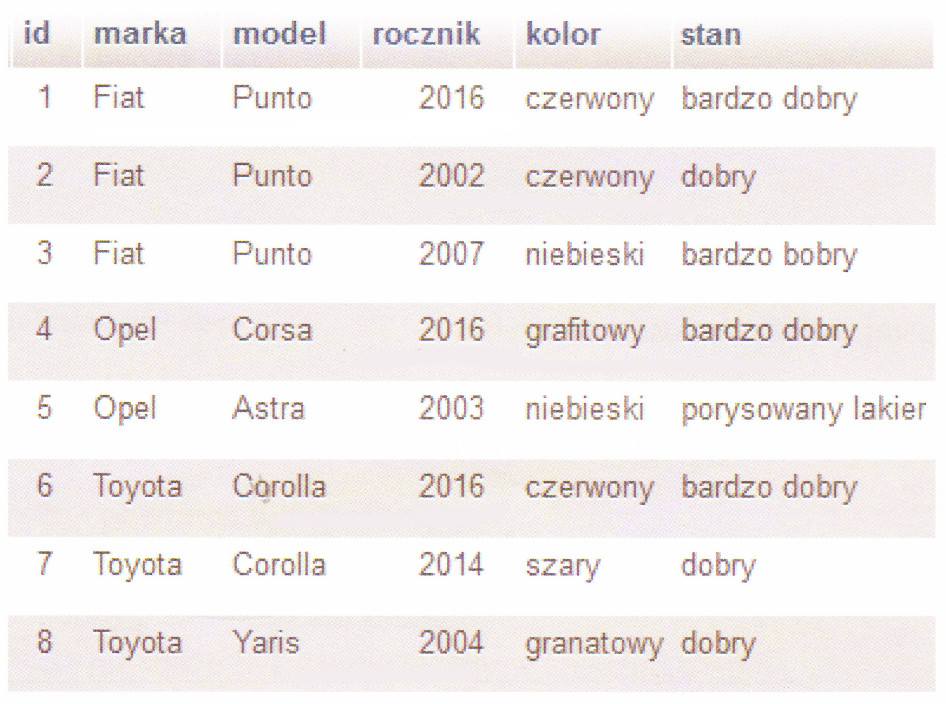
| id | nazwisko | imie | data_ur | ubezpieczony | ||||
|---|---|---|---|---|---|---|---|---|
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 1 | Kowalski | Jan | 2005-12-18 | 1 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 2 | Nowak | Adam | 2005-10-10 | 1 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 3 | Wisniewski | Antoni | 2005-06-14 | 0 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 4 | Lipska | Anna | 2006-04-12 | 1 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 5 | Tomaszewski | Pawel | 2006-07-11 | 0 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 6 | Kostarz | Julia | 2006-03-20 | 1 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 7 | Borewicz | Patryk | 2007-06-21 | 1 | |
| ✏️ Edytuj | 📋 Kopiuj | ⛔ Usuń | 8 | Koperski | Bartlomiej | 2001-09-10 | 0 | |
A. DROP FROM `uczniowie` WHERE data_ur LIKE "06"
B. DELETE FROM `uczniowie` WHERE data_ur LIKE "%-06-%"
C. DROP FROM `uczniowie` WHERE data_ur == #-06-#
D. DELETE FROM `uczniowie` WHERE data_ur LIKE "?-06-?"
Poprawnie wskazane zapytanie korzysta z instrukcji DELETE oraz operatora LIKE z odpowiednim wzorcem: "%-06-%". W kolumnie data_ur mamy daty zapisane w standardowym formacie ISO: RRRR-MM-DD, np. 2005-06-14. W takim formacie miesiąc zawsze znajduje się na pozycjach 6–7 i jest zapisany jako dwucyfrowa liczba z wiodącym zerem. Wzorzec "%-06-%" oznacza: dowolny ciąg znaków przed, dokładnie „-06-” w środku, oraz dowolny ciąg znaków po. Dzięki temu trafiamy w wszystkie daty, gdzie miesiąc to 06, czyli czerwiec, niezależnie od roku i dnia. To jest bardzo praktyczne podejście, gdy przechowujemy datę w typie DATE i chcemy filtrować po miesiącu bez dodatkowych funkcji. W MySQL operator LIKE działa na wartościach tekstowych, ale typ DATE jest w takim kontekście automatycznie konwertowany do postaci tekstowej w formacie 'YYYY-MM-DD', więc wzorzec z myślnikami jest jak najbardziej poprawny. W realnych projektach częściej stosuje się funkcje DATE_FORMAT albo MONTH(data_ur) = 6, bo to jest czytelniejsze i mniej podatne na pomyłki w zapisie wzorca. Jednak w tym zadaniu celem jest zrozumienie, jak działa LIKE, wildcard „%” oraz jak wygląda rzeczywisty format przechowywania daty. Dobrą praktyką jest też zawsze używanie pojedynczych cudzysłowów w SQL (np. '%-06-%'), choć MySQL akceptuje też podwójne w pewnych konfiguracjach. Moim zdaniem warto zapamiętać ten sposób myślenia: patrzysz na rzeczywisty zapis danych w kolumnie i dopasowujesz wzorzec tak, żeby trafić dokładnie ten fragment, który Cię interesuje (tu: '-06-').