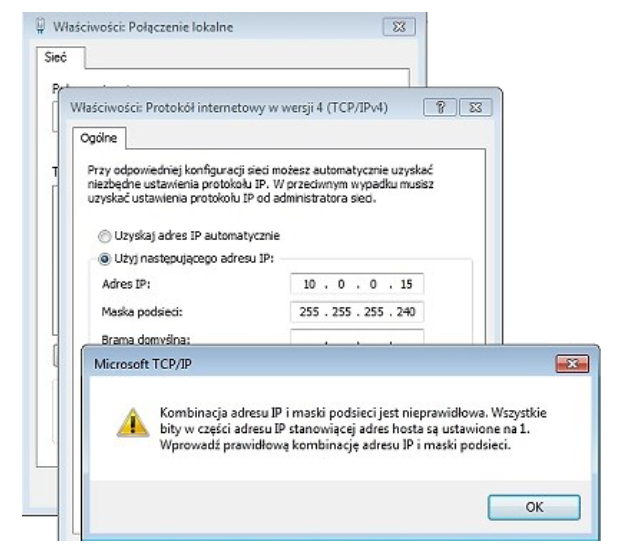
Pytanie 1
Aby określić długość prefiksu w adresie IPv4, należy ustalić
A. liczbę bitów o wartości 1 w części hosta adresu IPv4
B. liczbę bitów o wartości 0 w trzech pierwszych oktetach adresu IPv4
C. liczbę bitów o wartości 0 w pierwszych dwóch oktetach adresu IPv4
D. liczbę początkowych bitów o wartości 1 w masce adresu IPv4
Analizując niepoprawne odpowiedzi, konieczne jest zrozumienie, że każda z nich bazuje na błędnym podejściu do struktury adresów IPv4 oraz ich maskowania. Zaczynając od pierwszej propozycji, koncentruje się ona na liczbie bitów o wartości 0 w dwóch pierwszych oktetach, co jest mylące, gdyż istotne jest liczenie bitów z wartościami 1 w masce, a nie 0 w adresie. W przypadku drugiej odpowiedzi, odniesienie do trzech pierwszych oktetów nie ma sensu w kontekście ustalania prefiksu, ponieważ w praktyce maska definiuje, które bity są istotne dla określenia adresu sieci, a nie sposób zliczania zer w adresie. Ostatnia z propozycji sugeruje, że długość prefiksu można określić przez liczbę bitów mających wartość 1 w części hosta adresu, co jest fundamentalnie błędne, ponieważ prefiks powinien odnosić się do części sieciowej, a nie hosta. Tego typu błędne rozumienie prowadzi do nieefektywnej segmentacji sieci, co może skutkować problemami z routowaniem i bezpieczeństwem. Dlatego kluczowe jest, aby skupić się na właściwym obliczaniu długości prefiksu w kontekście maski podsieci, co jest podstawą prawidłowego zarządzania adresacją w sieciach IP.