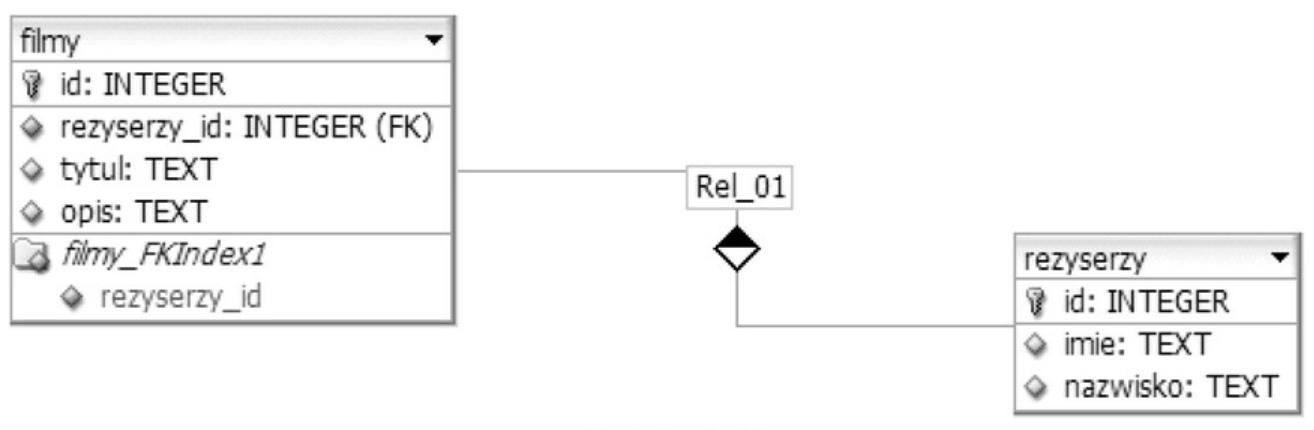
Pytanie 1
Aby baza danych działała poprawnie i konsekwentnie, konieczne jest wprowadzenie w każdej tabeli
A. klucza FOREIGN KEY z wartością NOT NULL
B. klucza obcego z wartością NOT NULL i UNIQUE
C. kluczy PRIMARY KEY i FOREIGN KEY
D. klucza PRIMARY KEY z wartością NOT NULL i UNIQUE
W kontekście baz danych, klucz PRIMARY KEY jest fundamentalnym elementem struktury każdej tabeli, ponieważ zapewnia unikalną identyfikację rekordów. Klucz ten musi spełniać dwie podstawowe zasady: być unikalny oraz nie pozwalać na wartości NULL. Dzięki temu każda linia w tabeli może być jednoznacznie zidentyfikowana, co jest niezbędne do zapewnienia integralności danych oraz efektywności operacji CRUD (tworzenie, odczyt, aktualizacja, usuwanie). Przykładem zastosowania klucza PRIMARY KEY może być tabela 'Użytkownicy', w której kolumna 'ID_Użytkownika' pełni rolę klucza głównego, zapewniając, że każdy użytkownik ma unikalny identyfikator. Wartości NULL w kluczu głównym byłyby problematyczne, ponieważ uniemożliwiałyby identyfikację danego rekordu. Dodatkowo, klucz ten może być użyty w relacjach między tabelami, gdzie klucz FOREIGN KEY w innej tabeli nawiązuje do PRIMARY KEY, tworząc spójną strukturę danych. Ustanawiając klucz PRIMARY KEY, projektanci baz danych mogą również efektywnie korzystać z indeksów, co przyspiesza operacje wyszukiwania oraz zwiększa wydajność bazy danych.