Pytanie 1
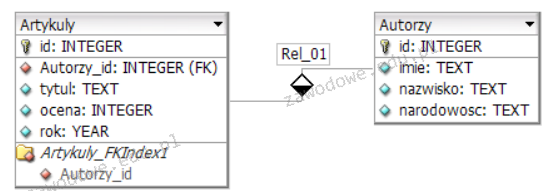
W bazie danych wykonano następujące polecenia dotyczące uprawnień użytkownika adam. Po ich realizacji użytkownik adam uzyska uprawnienia do
| GRANT ALL PRIVILEGES ON klienci TO adam REVOKE SELECT, INSERT, UPDATE ON klienci FROM adam |
A. tworzenia tabeli klienci oraz modyfikowania w niej danych
B. przeglądania tabeli klienci oraz dodawania do niej sektorów
C. modyfikowania danych i przeglądania tabeli klienci
D. usuwania tabeli lub jej rekordów
Prawidłowa odpowiedź dotycząca usunięcia tabeli lub jej rekordów wynika z analizy poleceń SQL które zostały wykonane na użytkowniku adam. Instrukcja GRANT ALL PRIVILEGES zapewnia użytkownikowi wszystkie dostępne uprawnienia do tabeli klienci w tym możliwość usunięcia zarówno całej tabeli jak i jej rekordów. Jednakże w dalszej kolejności polecenie REVOKE SELECT INSERT UPDATE ogranicza te konkretne uprawnienia. Pozostawia to użytkownikowi adam pełne prawo do korzystania z polecenia DELETE które umożliwia usunięcie poszczególnych rekordów oraz DROP które pozwala usunąć całą tabelę. Jest to kluczowe w zarządzaniu bazą danych zwłaszcza w kontekście zapewnienia integralności i bezpieczeństwa danych. W praktyce administratorzy baz danych muszą umiejętnie zarządzać uprawnieniami aby zapewnić odpowiedni poziom bezpieczeństwa oraz kontrolę dostępu zgodnie z najlepszymi praktykami branżowymi. Dzięki temu można uniknąć nieautoryzowanego dostępu do wrażliwych danych oraz przypadkowego usunięcia ważnych informacji