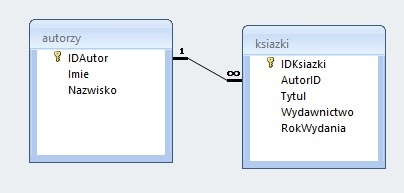
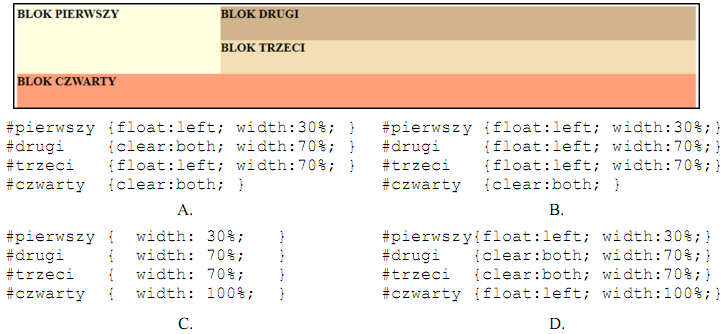
Pytanie 1
W języku PHPnie ma możliwości
A. zmienianie dynamiczne treści strony HTML w przeglądarce
B. przetwarzanie danych z formularzy
C. obróbka informacji przechowywanych w bazie danych
D. tworzenie dynamicznej zawartości strony internetowej
Odpowiedź dotycząca zmieniania dynamicznej zawartości strony HTML w przeglądarce jest poprawna, ponieważ PHP jest językiem skryptowym działającym po stronie serwera. Oznacza to, że PHP nie jest w stanie bezpośrednio modyfikować zawartości strony HTML po jej załadowaniu w przeglądarce użytkownika. Zamiast tego, PHP generuje HTML, który następnie jest przesyłany do przeglądarki. Dynamiczna zawartość strony może być generowana na podstawie danych z bazy danych lub formularzy, ale wszelkie zmiany w HTML po stronie klienta wymagają użycia języków, które działają po stronie przeglądarki, takich jak JavaScript. Przykładem może być sytuacja, w której użytkownik wypełnia formularz, a dane są przetwarzane przez PHP, które zwraca zaktualizowaną stronę. W przypadku potrzeby dynamicznych zmian, JavaScript może być użyty do manipulacji DOM po załadowaniu strony. Warto również zauważyć, że zgodnie z dobrymi praktykami, powinno się oddzielać logikę serwerową (PHP) od logiki klienckiej (JavaScript), co przyczynia się do lepszej struktury kodu i ułatwia jego utrzymanie.