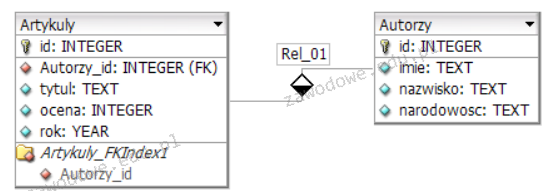
Pytanie 1
Podaj nazwę Systemu Zarządzania Treścią, którego logo jest widoczne na zamieszczonym rysunku?

A. Drupal
B. MediaWiki
C. WordPress
D. Joomla!
Joomla! to popularny system zarządzania treścią CMS który jest szeroko stosowany do tworzenia stron internetowych aplikacji online i portali. Dzięki swojej elastyczności Joomla! jest wybierany przez wiele firm i organizacji do zarządzania treścią online. System ten charakteryzuje się modułową architekturą która umożliwia łatwe rozszerzanie jego funkcjonalności za pomocą komponentów modułów i wtyczek. Jednym z głównych atutów Joomla! jest intuicyjny interfejs użytkownika który umożliwia zarządzanie treścią bez potrzeby głębokiej wiedzy technicznej. Dodatkowo Joomla! wspiera wiele języków co czyni go idealnym wyborem dla międzynarodowych organizacji. Warto również zaznaczyć że Joomla! jest open-source co oznacza że jest rozwijany przez społeczność programistów z całego świata którzy regularnie aktualizują i ulepszają oprogramowanie. Wybranie Joomla! jako CMS pozwala na korzystanie z dużej liczby szablonów i dodatków które umożliwiają personalizację witryny zgodnie z wymaganiami klienta. Dzięki solidnej bazie użytkowników i deweloperów Joomla! oferuje wsparcie techniczne i dokumentację która ułatwia rozwiązywanie problemów. W praktyce Joomla! jest wykorzystywany przez różnorodne witryny od małych blogów po rozbudowane platformy e-commerce co potwierdza jego wszechstronność i skuteczność.