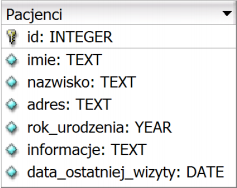
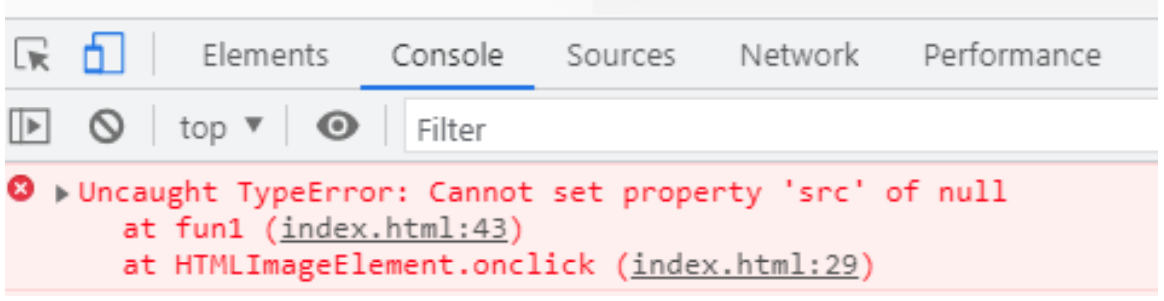
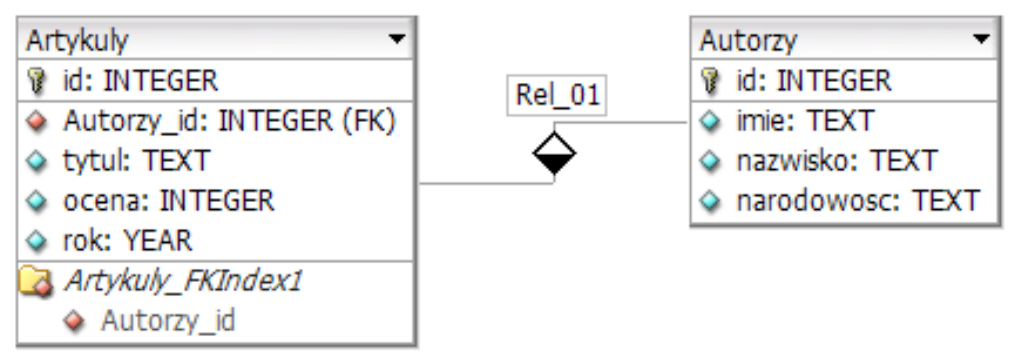
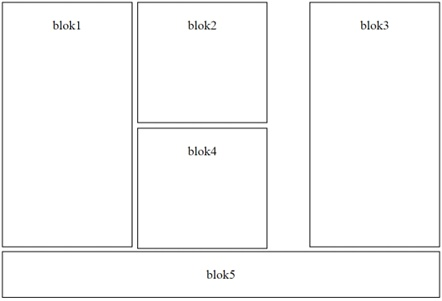
Pytanie 1
Jak wygląda poprawny zapis znaczników, który jest zgodny z normami języka XHTML i odpowiada za łamanie linii?
A. </br/>
B. </ br>
C. <br/>
D. <br/>
Zapis samozamykającego się znacznika <br/> jest poprawny zgodnie z standardem XHTML, który wymaga, aby znaczniki, które nie mają zawartości, były zapisane w sposób, który jednoznacznie wskazuje na ich samozamykającą się naturę. W XHTML każdy znacznik powinien być zamknięty, co oznacza, że nawet tagi samo zamykające się, takie jak <br/>, muszą zawierać ukośnik przed zamknięciem znacznika. Daje to pewność, że parsery XHTML poprawnie interpretują kod, co jest szczególnie ważne w kontekście obsługi różnorodnych przeglądarek, które mogą różnie reagować na błędnie sformatowany kod. Przykładem zastosowania <br/> jest łamanie linii w tekstach, gdzie chcemy uzyskać efekt nowego wiersza bez tworzenia nowego bloku, co jest typowe w celu zachowania struktury dokumentu HTML. Dobrą praktyką jest zawsze stosowanie poprawnych form zapisów zgodnych z obowiązującymi standardami, co nie tylko wpływa na poprawność działania kodu, ale również na jego czytelność i długoterminową utrzymywaność.