Pytanie 1
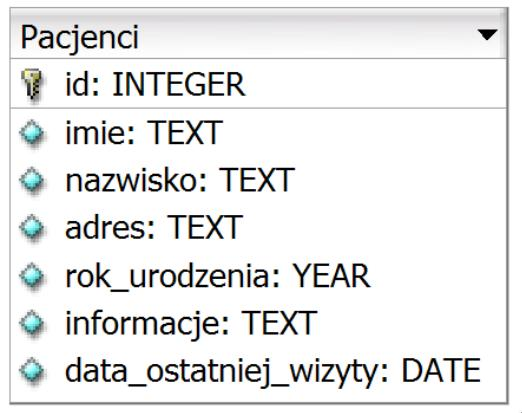
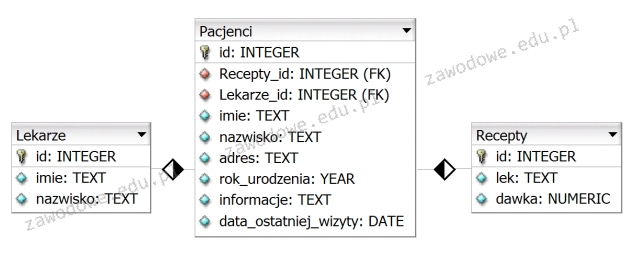
Na zaprezentowanym schemacie bazy danych biblioteka, elementy takie jak: czytelnik, wypożyczenie oraz książka stanowią
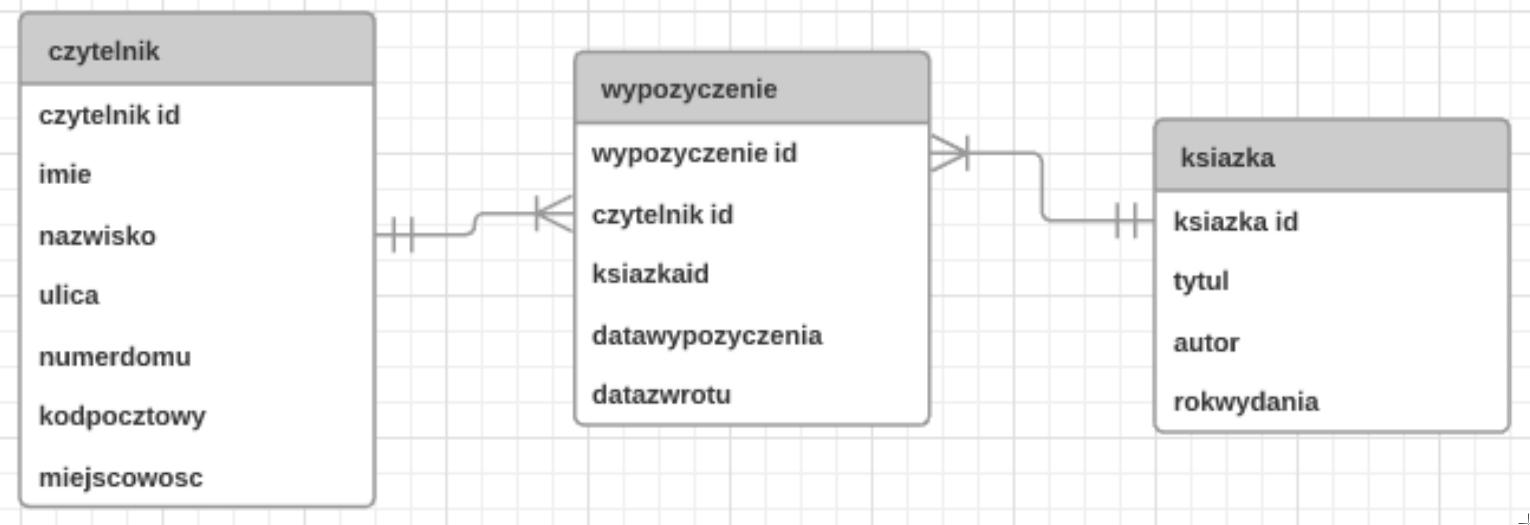
A. atrybuty
B. krotki
C. encje
D. pola
Prawidłowo – na takim schemacie bazy danych „czytelnik”, „wypożyczenie” i „książka” to encje. W modelowaniu danych najpierw identyfikujemy obiekty świata rzeczywistego, które chcemy odwzorować w systemie. W przypadku biblioteki naturalnymi obiektami są właśnie czytelnik, książka i konkretne wypożyczenie. W notacji ERD (Entity‑Relationship Diagram) każdy z tych obiektów opisujemy jako encję, a potem dopiero dodajemy jej atrybuty oraz relacje z innymi encjami. Na schemacie widzisz trzy prostokąty – to są właśnie encje. Każda encja ma zestaw atrybutów: dla encji „czytelnik” są to np. imię, nazwisko, ulica, miejscowość; dla encji „książka” – tytuł, autor, rok wydania; dla encji „wypożyczenie” – daty wypożyczenia i zwrotu, klucze obce do czytelnika i książki. W relacyjnej bazie danych te encje są potem najczęściej odwzorowane jako tabele: tabela CZYTELNIK, WYPOZYCZENIE, KSIAZKA. To jest dokładnie zgodne z dobrymi praktykami projektowania: najpierw model koncepcyjny (encje i relacje), dopiero później model logiczny (tabele, klucze, typy danych). Z mojego doświadczenia przy każdym poważniejszym projekcie bazodanowym analitycy najpierw rysują diagram encji, bo to pomaga zrozumieć domenę biznesową. Dzięki poprawnemu rozróżnieniu encji od atrybutów można uniknąć błędów typu powtarzanie tych samych danych w wielu miejscach czy trudności z raportowaniem. W bibliotece na przykład wypożyczenie musi być osobną encją, bo opisuje zdarzenie w czasie, ma własne atrybuty (daty) i łączy dwie inne encje relacjami. Taki sposób modelowania jest zgodny z klasycznymi podręcznikami baz danych (model encja‑związek) oraz z zasadami normalizacji.