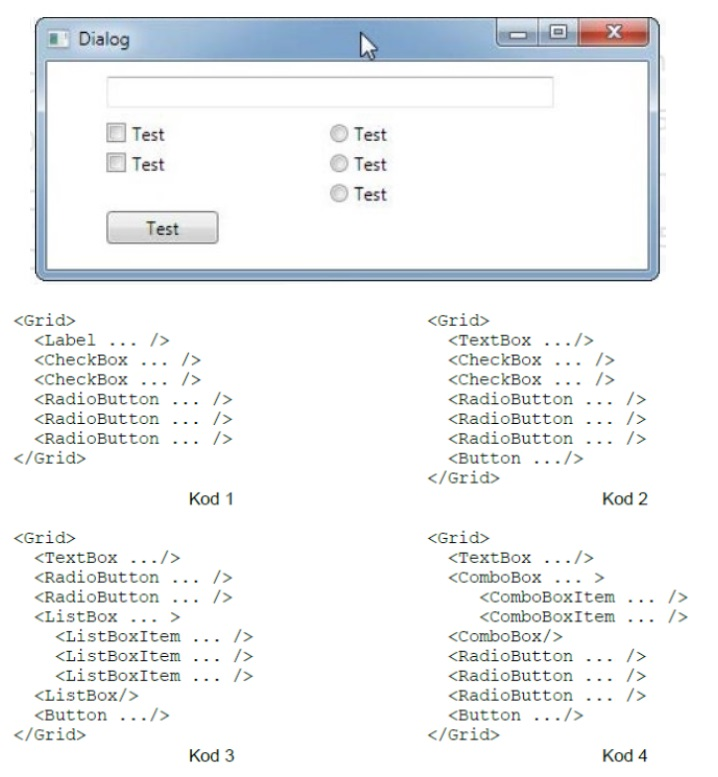
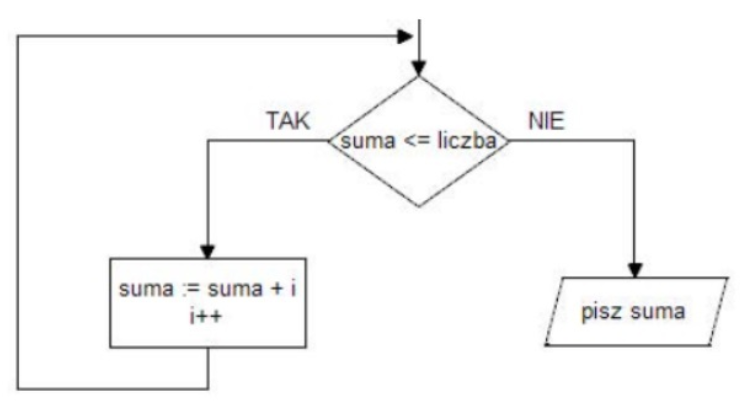
Pytanie 1
Podstawowym celem środowisk IDE takich jak: IntelliJ IDEA, Eclipse, NetBeans jest programowanie w języku:
A. Java
B. C++
C. Python
D. C#
IDE, czyli Zintegrowane Środowiska Programistyczne, takie jak IntelliJ IDEA, Eclipse czy NetBeans, od lat są uznawane za najważniejsze narzędzia do tworzenia aplikacji w języku Java. Te środowiska zostały od podstaw zaprojektowane właśnie z myślą o programistach Javy – wspierają typowe projekty Java SE, Java EE czy nawet JavaFX. Moim zdaniem, ich integracja z narzędziami takimi jak Maven, Gradle, testami jednostkowymi JUnit albo debuggerami Javy to prawdziwy game-changer. Na co dzień korzysta się tam z podpowiedzi składni, automatycznego refaktoringu, generatorów kodu i systemów kontroli wersji. Przykładowo, większość firm w Polsce, które tworzą oprogramowanie korporacyjne, wybiera właśnie te IDE do pracy z Java Spring Boot czy Hibernate. Nawet podczas nauki w technikum często pierwsze projekty Java robi się właśnie w Eclipse albo IntelliJ. Pewnie, można dorzucić pluginy do innych języków, ale to Java jest sercem tych środowisk i to dla niej są one najbardziej zaawansowane, zgodnie z najlepszymi wzorcami branżowymi. Jak patrzę na ogłoszenia o pracę, to praktycznie każda oferta na programistę Java zakłada znajomość choć jednego z tych IDE. To jasno pokazuje, że ich podstawowym celem jest ułatwienie i przyspieszenie tworzenia oprogramowania właśnie w tym języku.