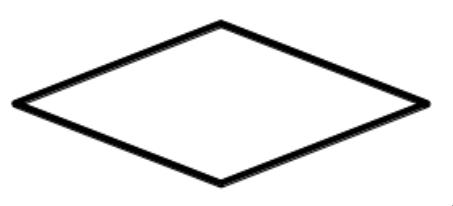
Pytanie 1
Prezentowany blok kodu ilustruje proces
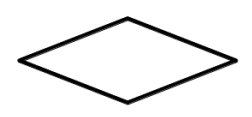
A. użycia zdefiniowanej procedury lub funkcji
B. realizacji zadania w pętli
C. podjęcia decyzji
D. załadowania lub wyświetlenia informacji
Pierwsza odpowiedź sugeruje że blok reprezentuje zastosowanie gotowej procedury lub funkcji co jest niepoprawne Romb w schematach blokowych nie jest używany do oznaczania procedur lub funkcji lecz do podejmowania decyzji Stosowanie procedur i funkcji zazwyczaj związane jest z blokami prostokątnymi symbolizującymi operacje a nie z decyzjami które wymagają warunkowego rozgałęzienia Druga odpowiedź wczytania lub wyświetlenia danych również nie jest poprawna Operacje związane z wczytywaniem i wyświetlaniem danych są zazwyczaj przedstawiane za pomocą bloków równoległoboków które obrazują wejście i wyjście danych Wczytywanie danych polega na pozyskaniu informacji z zewnętrznych źródeł lub użytkownika a wyświetlanie polega na prezentacji wyników jednak obie te czynności nie mają charakteru decyzyjnego Odpowiedź dotycząca wykonania zadania w pętli jest także błędna Pętle które umożliwiają powtarzanie określonych czynności są zazwyczaj wyrażane za pomocą konstrukcji prostokątnych z dodatkowymi wskaźnikami powrotu nie zaś za pomocą rombu który odzwierciedla logiczne warunkowe ścieżki przepływu danych Typowym błędem myślowym jest przypisywanie rombowi funkcji powiązanych z iteracjami lub operacjami co wynika z mylnego zrozumienia zasad tworzenia algorytmów w formie graficznej Intuicja podpowiada że decyzja i powtarzanie mogą być podobne jednak w diagramach blokowych różnią się symboliką i zastosowaniem