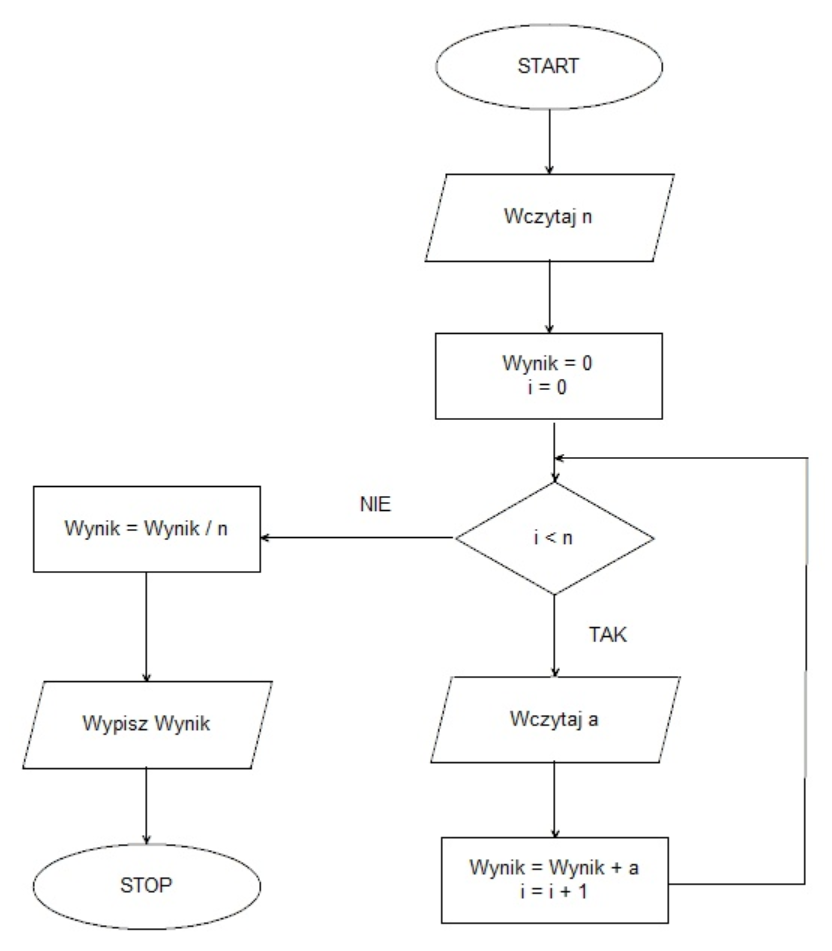
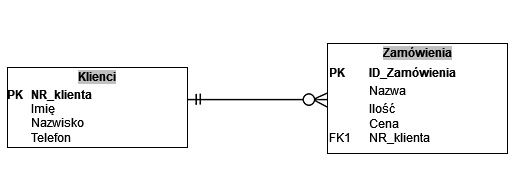
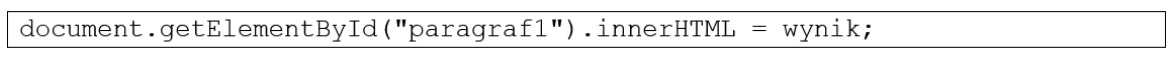Pytanie 1
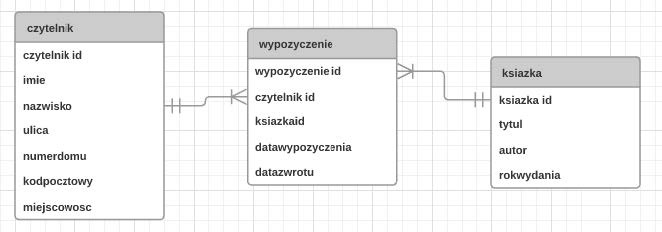
W języku PHP nie można wykonać
A. Dynamicznej zmiany treści strony HTML w przeglądarce
B. Operacji na danych zgromadzonych w bazie danych
C. Obsługiwania danych z formularzy
D. Tworzenia dynamicznej treści strony
Zmienianie dynamiczne zawartości strony HTML w przeglądarce nie jest możliwe za pomocą języka PHP, ponieważ PHP jest językiem skryptowym działającym po stronie serwera. Oznacza to, że PHP generuje kod HTML, który jest następnie przesyłany do przeglądarki, ale nie ma możliwości modyfikacji tego kodu po jego załadowaniu. Przykładowo, gdy użytkownik wypełnia formularz na stronie i przesyła dane, PHP może przetworzyć te dane na serwerze, ale wszelkie zmiany muszą być wysłane do przeglądarki jako nowa strona lub w odpowiedzi Ajax. W praktyce oznacza to, że dla dynamicznych interakcji na stronie, takich jak zmiana zawartości bez przeładowania, stosuje się JavaScript, który działa po stronie klienta i jest odpowiedzialny za manipulację DOM. W kontekście dobrych praktyk, warto pamiętać o rozdzieleniu logiki przetwarzania danych (PHP) i interakcji użytkownika (JavaScript), co prowadzi do bardziej modułowych i łatwych w utrzymaniu aplikacji webowych.